Speaker Labels in Transcription: How to Obtain Speaker Names for Accurate Transcription

Most developers treat transcription as a solved problem. Feed in audio, get back text. Done. But the moment you try to feed that text into an LLM to extract action items, flag objections, or summarize a sales call, you hit a wall.
The model cannot tell who said what. It sees a wall of text and has no idea whether the sentence "I will take care of the onboarding" came from your account executive or the client.
That is the core problem speaker labelling solves. It is not just a readability nicety. It is a structural requirement for any downstream NLP task that depends on who said something, not just what was said.
This guide covers the full technical picture: how speaker diarisation works under the hood, how different systems resolve generic labels into real names, where each approach breaks, and what the actual code looks like when you implement it.
The Difference Between Diarisation and Identification
These two terms get used interchangeably, and that confusion causes real engineering problems. They solve different questions.
Speaker diarisation answers: "How many people spoke, and when did each one speak?" It segments an audio stream into turns and assigns each turn a cluster ID.
Those IDs are arbitrary labels like Speaker_00, Speaker_01, and so on. The system has no knowledge of actual identity.
Speaker identification answers: "Who specifically is this person?" That requires mapping an acoustic cluster to a known entity. You need an external source of ground truth, whether that is a voice database, platform authentication data, or a human reviewer.
Most transcription APIs only give you diarisation. They cluster voices into buckets and label them with placeholder strings.
Turning those placeholders into real names is a separate engineering step, and most teams underestimate how much it matters.
Why Speaker Names Matter for LLMs and Downstream NLP
Large language models are powerful, but they are sensitive to structure. When you pass an unlabelled transcript to a model and ask it to assign responsibility for action items, it guesses. Sometimes it guesses right. Often it does not.
Here is a concrete example that illustrates the gap. Take this excerpt from a sales call:
The model cannot assign ownership because it does not know the conversation has multiple participants. Now add speaker labels:

The transcript content is identical. The only change is structural labelling, and it completely changes what the model can reliably extract. This applies to every NLP task that depends on speaker attribution: talk time analysis, sentiment by participant, compliance monitoring, coaching feedback, and much more.
How Speaker Diarisation Works Technically
Before you can understand how to get names, you need to understand the pipeline that produces labels in the first place. Diarisation is not a single model. It is a pipeline of several distinct stages.
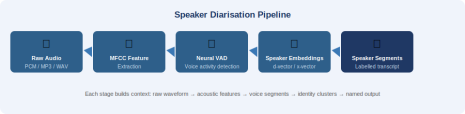
.
Stage 1: Feature Extraction via MFCCs
Raw audio arrives as a waveform, typically sampled at 16kHz for speech. The first step extracts Mel-Frequency Cepstral Coefficients (MFCCs), which compress the spectral shape of short audio frames into a compact numerical representation.
A standard configuration uses 13 MFCC coefficients computed over 25ms frames with 10ms hops.
Stage 2: Voice Activity Detection
Not all audio contains speech. Background noise, silence, and non-speech sounds need to be filtered out before diarisation runs. Modern systems use neural Voice Activity Detection (VAD) models trained on large speech corpora.
Silero VAD, for instance, runs a small LSTM network on 30ms chunks and outputs speech probability scores.
Stage 3: Speaker Embeddings
For each detected speech segment, a neural encoder maps the acoustic content into a fixed-size vector called a speaker embedding (also called a d-vector or x-vector depending on the architecture).
These vectors encode vocal characteristics in high-dimensional space. Two utterances from the same speaker cluster close together; utterances from different speakers cluster far apart.
Models like pyannote-audio 3.1 use a ResNet-based architecture trained on thousands of speakers.
The resulting embeddings work across languages because they capture biological vocal tract characteristics rather than phoneme patterns.
Notice the output: SPEAKER_00 and SPEAKER_01 are cluster IDs, not names. This is the fundamental limit of diarisation alone. The model knows these are two distinct voices. It does not know who they are.
Method 1: Platform Integration
If your audio comes from a video conferencing platform, this method beats everything else. Zoom, Google Meet, and Microsoft Teams all know who is in the meeting because participants authenticate with named accounts.
A bot that joins via the platform SDK or a meeting API can intercept the mapping between audio streams and participant identities in real time.
The key architectural insight: the platform already solved identity for you. You just need to read it.
This approach works because the platform knows which microphone audio belongs to which authenticated user.
The bot does not need to do acoustic matching. It reads an event stream from the platform where each audio packet is tagged with the participant user ID, and the platform already maps user IDs to display names.
The limitation is scope: this only works for conversations on supported platforms. Pre-recorded audio files, phone calls, in-person meetings, and podcast recordings do not have this identity layer built in.
Method 2: Voiceprint Enrolment and Matching
For environments without platform authentication, you can build your own identity layer using voice biometrics. The process has two phases: enrolment and matching.
During enrolment, you collect a labelled audio sample from each known speaker (typically 30 to 180 seconds of clean speech), extract speaker embeddings from that sample, and store the averaged embedding vector in a database keyed to the person's name.
During inference, you extract embeddings from each diarised segment and compute cosine similarity against every enrolled voiceprint.
If the best match exceeds a confidence threshold, you assign that name. Otherwise, you fall back to a generic label.
Voiceprint matching works well for organisations with a stable, known set of speakers. Call centres, executive teams, and recurring interview panels all fit this profile.
The accuracy drops when audio quality degrades, when speakers have very similar vocal characteristics, or when someone speaks in a very short utterance (under two seconds makes reliable embedding extraction difficult).
One genuinely important note: voice embeddings constitute biometric data under GDPR Article 9, CCPA, and the Illinois BIPA.
Storing them without explicit informed consent carries serious legal risk. Build your consent flow before you build your voiceprint pipeline.
Method 3: In-Audio Name Extraction with NLP
People introduce themselves constantly during conversations. "Hi everyone, I'm Priya from the engineering team." "Let me hand over to Marcus." "Thanks, Sarah, that was helpful."
An intelligent transcription system can detect these patterns and use them to anchor speaker labels to real names.
This method combines the labelled transcript output from diarisation with a named entity recognition pass that looks for self-identification patterns and direct address patterns.
This approach requires no pre-enrolment and no platform integration. It works on any recording where speakers introduce themselves. The obvious weakness is that not all conversations include verbal introductions.
In a meeting between colleagues who know each other well, nobody says their own name. Pair this method with manual assignment as a fallback.
Method 4: Calendar and Participant Roster Matching
Video conferencing platforms attach calendar metadata to meetings. When a transcription tool reads the calendar invite for a recorded meeting, it already has a list of expected attendees and their emails.
The challenge is connecting that list to the diarised speaker segments.
The bridge is fuzzy name matching. Platform APIs often expose participant display names in real time.
You match those display names against the calendar attendee list to resolve full names and email addresses.
This method works particularly well for enterprise meeting tools where calendar integration is standard. Once you resolve display names to calendar entries, you unlock email-based identity, which lets you build features like automatic CRM updates, personalised follow-up drafts, and per-attendee analytics dashboards.
Where Diarisation Breaks?
Every method above has failure conditions. You will encounter these in production. Here is what actually breaks and how to handle it.
Overlapping Speech
When two people talk simultaneously, diarisation models have to make a decision about which speaker "owns" the audio segment.
Most models assign the segment to a single speaker even when two voices are present. Overlapping speech is the single biggest source of diarisation errors in real meeting audio.
The practical mitigation is to separate speaker audio streams at capture time using multi-channel recording, where each microphone feeds a separate channel.
Short Utterances
Speaker embedding models need enough audio to compute a reliable representation. Utterances under one second produce noisy embeddings.
Common short responses like "yes," "got it," "agreed," and "okay" frequently get misassigned, especially in fast-moving conversations.
One approach is to accumulate embeddings across multiple short utterances from the same speaker before making a final assignment, rather than deciding per segment.
Speaker Count Estimation
Most diarisation pipelines require you to specify the number of speakers, or they run an automatic estimation that adds its own error. When the count is wrong, the clustering goes wrong too. A pipeline told to find three speakers in a five-person meeting will hallucinate speaker merges. If you know the participant count from calendar data, pass it explicitly rather than relying on automatic estimation.
What is the Use Case of Speaker Diarisation?
1. Sales Intelligence
Sales coaching platforms track talk time ratios, question frequency, and objection handling patterns.
For any of that to work, the system needs to separate the salesperson segments from the prospect segments.
Platform integration provides this cleanly for video sales calls. Once you have attributed transcripts, you can compute talk time per speaker in a few lines of code.
2. Legal and Compliance
Virtual deposition software and compliance recording systems require precise speaker attribution for the record.
Every question, answer, and objection must be attributed to the correct party. In these contexts, the gold standard is platform integration plus mandatory manual review before any transcript enters the legal record.
Automated attribution supports the reviewer. It does not replace them.
3. Telehealth and Clinical Documentation
Clinical conversation AI needs to separate physician speech from patient speech for documentation automation.
A physician asking "do you have chest pain?" must not be attributed to the patient, and vice versa. HIPAA-compliant platforms handle identity at the session level, which makes platform integration the natural choice.
Voiceprint databases in clinical settings carry additional regulatory considerations under both HIPAA and GDPR.
Evaluating Diarisation Quality in Your Pipeline
If you build or integrate a diarisation system, you need metrics to know whether it is working. The standard evaluation metric is Diarisation Error Rate (DER), defined as:
DER = (false alarm + missed speech + speaker confusion) / total speech duration
Build a reference dataset from your actual audio (not benchmark datasets). Benchmark datasets use controlled studio recordings. Your real audio sounds different. Test on production-representative samples and measure DER on a rolling basis after every pipeline update.
Conclusion
The diarisation pipeline, the voiceprint matching logic, the calendar fuzzy matching, the platform OAuth integration, if you are building a product that records and analyses meetings, you do not want to maintain all of this yourself.
These systems break in subtle ways when audio conditions change, and they require ongoing tuning as platforms update their APIs.
Meetstream.ai is a meeting intelligence tool built specifically for teams that need accurate, named transcripts without the infrastructure overhead.
It connects to Zoom, Google Meet, and Microsoft Teams, pulls authenticated participant identity from the platform, and produces clean transcripts where every line is attributed to a real name, not a generic speaker cluster.

