Zero-Shot Topic Classification for Meeting Transcripts

Most NLP classification systems require labeled training data. You define your categories, annotate hundreds or thousands of examples, fine-tune a model, and ship. That workflow breaks down the moment your categories change. If you want to detect meeting topics like "technical discussion" or "pricing objection" and you have no labeled transcripts, the traditional approach leaves you stuck before you even start.
Zero-shot text classification sidesteps this entirely. Instead of learning from labeled examples, these models use natural language inference to decide whether a piece of text is consistent with a category label written in plain English. You can define entirely new categories at inference time, and the model reasons about fit without ever having seen a training example for that exact label.
For meeting transcript analysis, this is a practical unlock. Sales calls contain deal discussions, objections, and next steps. Engineering syncs contain blockers, technical decisions, and architecture debates. Customer success calls contain churn signals, feature requests, and escalation moments. These categories overlap across customers, change over time, and would require enormous annotation effort to learn in a supervised way. Zero-shot classification handles all of them with zero labeled data.
In this guide, you will build a meeting topic classifier using Hugging Face transformers and the MNLI-based pipeline. We will apply it to transcripts pulled from the MeetStream API, segment transcripts by speaker turn, classify each turn, and produce a structured topic timeline. Let's get into it.
How Zero-Shot Classification Works with MNLI Models
The model architecture behind zero-shot classification is natural language inference (NLI), trained on the Multi-Genre Natural Language Inference (MNLI) corpus. NLI models learn to classify pairs of sentences as entailment, contradiction, or neutral. "The dog is outside" entails "An animal is outside." It contradicts "The dog is inside." It is neutral to "The dog is brown."
Zero-shot classification repurposes this. Given a piece of text and a candidate label, it constructs a hypothesis: "This text is about [label]." It then runs the NLI model to score whether the original text entails that hypothesis. The score becomes a confidence value. Repeat across all candidate labels, normalize with softmax, and you have a probability distribution over your categories.
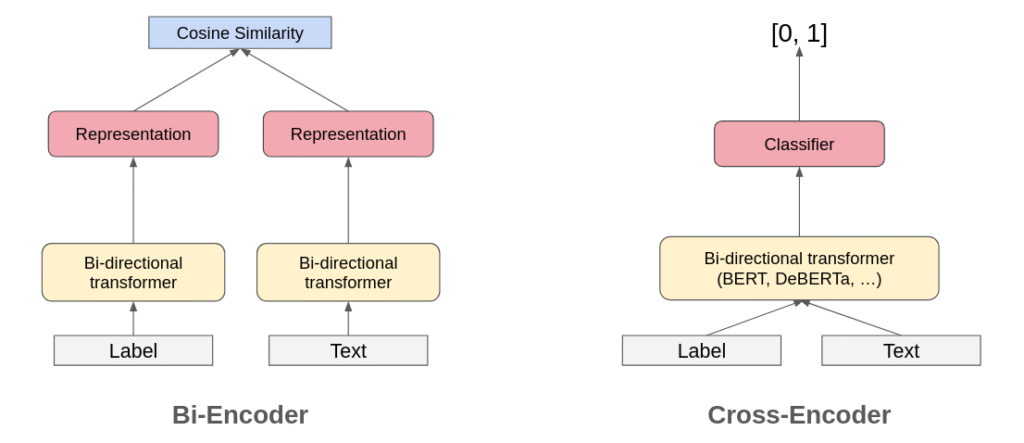
The Hugging Face pipeline("zero-shot-classification") handles this under the hood. The default model is facebook/bart-large-mnli, which is large but accurate. A lighter option is cross-encoder/nli-deberta-v3-small, which trades some accuracy for significantly lower latency and memory footprint. For meeting transcripts where you are classifying hundreds of short turns, the smaller model is often the right tradeoff.
from transformers import pipeline
classifier = pipeline(
"zero-shot-classification",
model="cross-encoder/nli-deberta-v3-small"
)
labels = ["action item", "technical discussion", "blocker", "decision made", "open question"]
text = "We need to migrate the auth service before we can ship the new login flow. That is blocking the entire release."
result = classifier(text, candidate_labels=labels)
print(result["labels"][0], result["scores"][0])
# blocker 0.847
Fetching Transcripts from MeetStream
Before classification, you need transcript data. MeetStream delivers transcripts via webhook as the meeting runs, and also makes them available via GET endpoint after the meeting ends. The transcription.processed webhook fires per utterance and includes speakerName, new_text, and end_of_turn.
import httpx
API_KEY = "YOUR_API_KEY"
BOT_ID = "your-bot-id"
response = httpx.get(
f"https://api.meetstream.ai/api/v1/transcript/{BOT_ID}/get_transcript",
headers={"Authorization": f"Token {API_KEY}"}
)
transcript = response.json()
# Returns list of {speaker, text, timestamp} objects
Each item in the transcript list represents a speaker turn. This is the unit you want to classify. A single turn is typically one to four sentences, which is the right length for NLI-based classification. Longer passages dilute the signal because they may contain multiple topics.
Classifying Speaker Turns at Scale
The naive approach is to classify each turn one at a time. For a 60-minute meeting with 200 turns, this works fine on CPU in a few minutes. If you need lower latency, batch inference is significantly faster.
from transformers import pipeline
from typing import List, Dict
classifier = pipeline(
"zero-shot-classification",
model="cross-encoder/nli-deberta-v3-small",
device=0 # use -1 for CPU
)
TOPIC_LABELS = [
"action item",
"technical discussion",
"blocker",
"decision made",
"open question",
"small talk"
]
def classify_turns(turns: List[Dict]) -> List[Dict]:
texts = [t["text"] for t in turns]
results = classifier(texts, candidate_labels=TOPIC_LABELS, batch_size=16)
annotated = []
for turn, result in zip(turns, results):
annotated.append({
"speaker": turn["speaker"],
"text": turn["text"],
"timestamp": turn.get("timestamp"),
"topic": result["labels"][0],
"confidence": round(result["scores"][0], 3)
})
return annotated
The batch_size=16 parameter passes 16 (text, hypothesis) pairs to the model at once, which saturates GPU throughput and reduces wall-clock time by 4-6x versus sequential calls.
Filtering Low-Confidence Predictions
Zero-shot classification will always return a top label, even when the model is not confident. A confidence threshold prevents noise from polluting your downstream analysis. For meeting transcripts, a threshold of 0.45 works well. Turns below this cutoff are labeled "uncertain" and excluded from topic aggregations.
CONFIDENCE_THRESHOLD = 0.45
def filter_predictions(annotated_turns: List[Dict]) -> List[Dict]:
for turn in annotated_turns:
if turn["confidence"] < CONFIDENCE_THRESHOLD:
turn["topic"] = "uncertain"
return annotated_turns
In practice, small-talk turns and filler utterances ("Right, yeah, okay") cluster below the threshold. This is expected behavior and it is useful. Those turns carry no analytical signal.
Building the Topic Timeline
Once you have per-turn classifications, you can build a topic timeline that shows how a meeting progressed. Grouping consecutive turns with the same topic into segments gives you a readable narrative.
from itertools import groupby
def build_topic_timeline(annotated_turns: List[Dict]) -> List[Dict]:
timeline = []
for topic, group in groupby(annotated_turns, key=lambda t: t["topic"]):
segment_turns = list(group)
confident_turns = [t for t in segment_turns if t["topic"] != "uncertain"]
if not confident_turns:
continue
timeline.append({
"topic": topic,
"start_time": segment_turns[0].get("timestamp"),
"end_time": segment_turns[-1].get("timestamp"),
"turn_count": len(segment_turns),
"speakers": list({t["speaker"] for t in segment_turns})
})
return timeline
# Example output:
# [
# {"topic": "technical discussion", "start_time": "0:02", "turn_count": 8, "speakers": ["Alice", "Bob"]},
# {"topic": "blocker", "start_time": "0:14", "turn_count": 3, "speakers": ["Bob"]},
# {"topic": "decision made", "start_time": "0:18", "turn_count": 2, "speakers": ["Alice", "Carol"]}
# ]
Topic Frequency Analysis and Meeting Scoring
The topic timeline is useful for inspection. Topic frequency analysis is useful for scoring meeting quality and detecting patterns across many meetings. A meeting with 60% small talk and 5% action items is a different kind of meeting than one with 40% technical discussion and 25% decisions.
from collections import Counter
def summarize_meeting_topics(annotated_turns: List[Dict]) -> Dict:
topics = [t["topic"] for t in annotated_turns if t["topic"] != "uncertain"]
total = len(topics)
if total == 0:
return {}
counts = Counter(topics)
return {
topic: {"count": count, "pct": round(count / total * 100, 1)}
for topic, count in counts.most_common()
}
# Example output:
# {
# "technical discussion": {"count": 42, "pct": 38.2},
# "action item": {"count": 18, "pct": 16.4},
# "blocker": {"count": 12, "pct": 10.9},
# "decision made": {"count": 9, "pct": 8.2},
# "open question": {"count": 7, "pct": 6.4}
# }
Integrating with a MeetStream Webhook
For real-time topic detection during a meeting, connect the classifier to the transcription.processed webhook. Each payload contains a completed speaker turn with end_of_turn: true. Classify immediately and push the result to wherever your application consumes it.
from fastapi import FastAPI, Request
from transformers import pipeline
import json
app = FastAPI()
classifier = pipeline(
"zero-shot-classification",
model="cross-encoder/nli-deberta-v3-small"
)
TOPIC_LABELS = ["action item", "technical discussion", "blocker", "decision made", "open question"]
@app.post("/webhook/transcription")
async def handle_transcription(request: Request):
body = await request.json()
if not body.get("end_of_turn"):
return {"status": "skipped"}
text = body.get("new_text", "")
if len(text.strip()) < 10:
return {"status": "too_short"}
result = classifier(text, candidate_labels=TOPIC_LABELS)
topic = result["labels"][0]
confidence = result["scores"][0]
if confidence > 0.45:
# Push to your application: Slack, database, dashboard
print(f"{body['speakerName']}: [{topic}] {text}")
return {"topic": topic, "confidence": confidence}
Deploy this webhook handler behind your MeetStream bot configuration, and every end-of-turn event becomes a classified, structured data point in real time. You can feed this into a live meeting dashboard, a coaching overlay for sales reps, or an async Slack digest after the meeting ends.
Conclusion
Zero-shot topic classification removes the labeling bottleneck from meeting analytics. You define what matters in plain English, and NLI-based models reason about fit without training data. The Hugging Face pipeline makes the implementation straightforward, and MeetStream's transcript API gives you structured, speaker-labeled text to work with from day one. If you are building meeting intelligence tools, this is one of the higher-leverage NLP techniques to add to your stack. The MeetStream dashboard is a good place to start if you want a bot running in your next meeting.
What is zero-shot text classification?
Zero-shot text classification is a technique where a model assigns a piece of text to a category without having been trained on labeled examples for that category. It works by using natural language inference models to score how well a text entails a hypothesis of the form "this text is about [label]." This makes it possible to define new categories at inference time without any annotation work.
Which transformer model is best for zero-shot classification on meeting transcripts?
cross-encoder/nli-deberta-v3-small is a strong default for meeting transcripts. It is significantly smaller than facebook/bart-large-mnli while retaining good accuracy on short texts. For production workloads where you are classifying hundreds of speaker turns per meeting, the latency difference matters. If accuracy is paramount and latency is less constrained, bart-large-mnli performs better on ambiguous utterances.
How do I handle meeting topic detection for short utterances?
Short utterances (under 10 words) often score low confidence across all labels because there is not enough context for the NLI model to reason about. Apply a minimum length filter before classification and mark very short turns as uncertain. Alternatively, you can concatenate consecutive short turns from the same speaker before classifying, which gives the model more context and improves accuracy.
Can I add custom topic labels specific to my domain?
Yes. The zero-shot approach accepts any labels you define. For a sales call classifier, you might use labels like "pricing discussion", "competitor mention", "objection", "next steps", and "executive sponsor". For a product planning call, "feature request", "scope change", "technical constraint", and "priority decision" work well. The model does not need to be retrained when you change or add labels.
What is the difference between topic classification and NER for meeting transcripts?
Topic classification assigns a semantic category to an entire utterance or span of text. Named entity recognition (NER) extracts specific mentions of people, organizations, products, and other entity types from within the text. They are complementary. Topic classification tells you that a turn is a "blocker"; NER tells you that the blocker involves a specific person or system name. For rich meeting analytics, you typically want both running in the same pipeline.
Frequently Asked Questions
How does zero-shot topic classification work for meeting transcripts?
Zero-shot classification uses a model pre-trained on natural language inference (NLI) to determine whether a text snippet entails a candidate label. For meeting transcripts, you define topic labels like "pricing discussion" or "technical issue" and pass each transcript segment through the model without any task-specific training data.
Which zero-shot model performs best for meeting topic classification?
facebook/bart-large-mnli and cross-encoder/nli-deberta-v3-large are the top performers for zero-shot classification of business meeting content. BART-large-MNLI runs at about 50 segments per second on a GPU, while DeBERTa-v3 is slower but more accurate on nuanced topic boundaries. For production, use BART unless accuracy is critical.
How many candidate labels can I use in zero-shot classification?
Models like BART-MNLI handle up to 20-30 candidate labels per inference call before accuracy degrades. For meeting transcripts with many possible topics, use a two-stage approach: a coarse classifier with 5-8 broad categories followed by a fine-grained classifier only for the relevant category. This also reduces inference cost.
How do I evaluate zero-shot classification accuracy on meeting data?
Label 200-300 transcript segments manually and compute macro F1 against your candidate label set. Zero-shot accuracy on meeting content typically runs 0.62-0.75 macro F1, which is sufficient for routing and filtering but not for billing or compliance decisions. For higher-stakes use cases, collect enough labeled data to fine-tune a smaller model.


