Meeting Automation for Remote Teams: What to Build and How

Remote teams run on meetings they can't always attend live. Someone's in Singapore, someone's in Berlin, and the weekly engineering sync happens at 7 AM in San Francisco. You can record everything with Zoom's native recorder, but now you've got a folder of .mp4 files nobody watches, zero searchability, and action items that live in one person's notes app until they get lost. That's the reality most remote tools leave you with.
Remote meeting automation is the gap between "we have recordings" and "our team actually benefits from what was said." The native meeting platforms handle the real-time communication well. What they don't provide is an automated pipeline from call to searchable transcript to async summary pushed to the right Slack channel to a tracked action item in your project management tool. You have to build that.
Distributed teams lose an estimated 20% of decision context to timezone gaps, according to research from GitLab's remote work studies. Decisions get made in one timezone, documented badly, and re-litigated in the next meeting. The fix isn't more meetings. The fix is infrastructure that captures what was decided and puts it where people can find it without asking someone to replay a 45-minute recording.
This guide is for developers building tools for remote teams, whether that's an internal tool for your own company or a product you're shipping to other organizations. We'll cover what remote teams actually need, the technical approach for each component, and how to wire it together using a meeting API as the recording and transcription layer. You can realistically have a working prototype in a weekend.
Why Native Meeting Tools Fall Short for Remote Teams
Zoom, Google Meet, and Microsoft Teams are excellent at connecting people in real time. Their async and automation features are afterthoughts. Here's what breaks down specifically for distributed teams:
Native transcripts exist but aren't searchable across meetings. You can find text within a single transcript, but asking "in which meeting did we decide to deprecate the v1 API?" returns nothing useful. There's no cross-meeting query interface.
Summaries, where they exist, are generic paragraphs with no structure. They don't distinguish decisions from discussion, action items from context. A useful async summary for a remote teammate is a typed document: what was decided, who owns what by when, what's blocked. That requires extraction logic, not just a meeting summarizer.
Notifications don't route to where remote teams live. A remote team's source of truth is Slack (or Teams), not the meeting platform's notification system. If a summary is only visible inside Zoom, someone in a different timezone has to know to go look for it. Push to Slack, and they see it when they wake up.
The access control model is also wrong. Native meeting platforms control who can access recordings based on meeting membership. Your internal tool or product needs to control access based on your own user model, who should see this transcript, which data should be retained, which recordings are sensitive enough to require restricted access.
Core Feature 1: Async Summaries Pushed to Slack
The highest-value automation for remote teams is automatic post-meeting summaries delivered to Slack. When a meeting ends, the relevant Slack channel gets a structured message with what was decided, who owns what, and what was deferred. The teammate in a different timezone wakes up, reads it in 60 seconds, and is caught up without watching a recording.
Technical implementation: deploy a bot to the meeting using the MeetStream API with callback_url set to your webhook handler. When transcription.processed fires, send the transcript through your summarization pipeline. The prompt matters here, a generic "summarize this meeting" produces a paragraph. A structured prompt produces JSON:

{
"decisions": [{"decision": "string", "context": "string"}],
"action_items": [{"owner": "string", "task": "string", "due": "string|null"}],
"deferred": ["string"],
"attendees": ["string"]
}Format that JSON as a Slack Block Kit message. Decisions in one section, action items formatted as checkboxes (Slack supports interactive checkboxes that can mark items complete), deferred topics in a collapsible section. Post to the channel associated with the meeting, you can store the channel mapping when the bot is deployed.
The owner name in action items needs to resolve to a Slack user ID for proper @mentions. Build a name-to-Slack-user lookup from your user database. Fuzzy match helps with transcription errors ("John" might be in the transcript when the Slack username is "johnny.chen").
Core Feature 2: Searchable Transcript Archive
A transcript that you can't search is just a long text file. A searchable transcript archive that spans all of your team's meetings for the past year is organizational memory. "What did we decide about the pricing model in Q3?" becomes answerable in under 5 seconds.
The data model is straightforward. Each transcription.processed event writes to a database table with: meeting ID, date, participants, and an array of speaker-attributed segments with timestamps. Full-text search indexed on the segment text, with filter dimensions on date range, participant, and meeting type.
For the search experience, there are two approaches. Pure text search using PostgreSQL's built-in full-text search or Elasticsearch handles keyword queries well. For semantic search ("meetings where we discussed switching infrastructure providers"), you embed each segment with a vector embedding model and run nearest-neighbor queries against a vector store. The semantic approach is significantly more useful for knowledge retrieval but requires more infrastructure.
A practical hybrid: text search for exact queries, semantic search as a fallback when text search returns few results. This gives good coverage without requiring you to embed every segment on day one, you can start with text search and add semantic search when you have enough transcripts to justify the infrastructure.
Importantly, handle async meeting summaries for remote team members who want to catch up by browsing recent meetings. A "what I missed" feed, meeting summaries from the past 24 hours relevant to your team or project, is one of the highest-engagement features you can build on top of the transcript archive.
Core Feature 3: Cross-Timezone Meeting Records
Timezone handling is where a lot of remote team tools get it wrong. A meeting at 9 AM San Francisco time is 5 PM in London and midnight in Singapore. Your tool needs to display times in each user's local timezone consistently, not just store UTC and hope the frontend handles it correctly.
The recording layer handles this fine, UTC timestamps are correct for storage and querying. The display layer needs per-user timezone preferences and localized formatting. Store user timezone in your user model. When rendering meeting times, convert server-side to the requesting user's timezone rather than relying on JavaScript timezone detection, which behaves inconsistently across browsers.
For cross-timezone teams, a meeting timeline view is more useful than a flat list. Group meetings by week, show the day-of-week in the context of who called it, and highlight when a meeting falls outside normal working hours for a participant. This surfaces the actual cost of cross-timezone collaboration, which helps teams optimize their meeting schedules over time.

The MeetStream webhook system provides UTC timestamps for all bot events: join time, meeting start, meeting end. These map cleanly to your cross-timezone display needs. No extra processing required on the recording side.
Core Feature 4: Action Item Tracking Without Manual Notes
Action items from meetings are the contract between what was decided and what actually happens. Most teams track them in a shared doc that nobody updates, a Notion page that gets stale after week two, or not at all. The automated version tracks every action item from every meeting and surfaces the ones that are late or unaddressed.
The extraction pipeline is the same as the Slack summary: extract structured action items from the transcript post-call. The difference is the tracking lifecycle. Each action item gets a record in your database with: owner (user ID), task description, source meeting ID, due date (extracted or null), creation time, status (open/complete/deferred), and last updated time.
Reminder logic: run a daily job that finds action items where due date is tomorrow or past due, and sends a DM to the owner in Slack. This is the part that makes the system actually close the loop. Extraction without follow-up is just better notes, extraction with automated reminders is accountability infrastructure.
The completion mechanic matters. If owners have to log into a separate tool to mark items complete, compliance drops immediately. Build the completion into Slack: the daily reminder includes a button that marks the item complete without leaving Slack. Alternatively, if action items sync to a project management tool like Linear or Jira, use their APIs to check completion status automatically.
Building the Integration Architecture
For a weekend prototype, the architecture is deliberately simple: one webhook handler, one database, one Slack integration. Here's the flow:

Bot deployment trigger: when a calendar event with a meeting link is created (via Google Calendar webhook) or when a user manually creates a bot via your app UI, call POST https://api.meetstream.ai/api/v1/bots/create_bot with the meeting link, bot name, and your callback URL. Store the bot ID and associated metadata (meeting title, channel, organizer) in your database.
Webhook handler: a single HTTP endpoint that receives all MeetStream webhook events. On bot.inmeeting, log the start time. On bot.stopped, log end time. On transcription.processed, kick off the async processing pipeline: summarization, action item extraction, Slack post, transcript storage. Use a job queue (BullMQ, Celery, or even a simple database-backed queue) so the webhook handler returns immediately and processing happens asynchronously.
Database: one table for meetings, one for transcripts (segments), one for action items. That's enough for the core features. Add full-text indexes on the transcript segments table from the start. Retrofitting search indexes is annoying and requires downtime if the table has grown large.
Slack integration: a Slack app with a bot token. Post summaries to channels via the chat.postMessage API. Send DM reminders via the conversations.open + chat.postMessage pattern. The interactive checkbox for marking action items complete uses Slack's Block Kit interactive components and requires a /slack/interactions endpoint in your app.
Platform Coverage Across Remote Team Tools
Remote teams use different meeting platforms based on their organization. A developer tool for remote teams has to work across Google Meet, Zoom, and Microsoft Teams without requiring different code paths or different products. The MeetStream API abstracts platform differences at the bot deployment layer, you call the same endpoint with any meeting link.
One setup note: Zoom requires installing the MeetStream app in your Zoom account before bots can join Zoom meetings. Google Meet and Microsoft Teams work without any platform-side setup. If you're building for organizations that use Zoom, document this dependency clearly in your onboarding flow. It's a one-time setup per Zoom account, not per meeting, so the friction is low but it needs to be handled upfront.
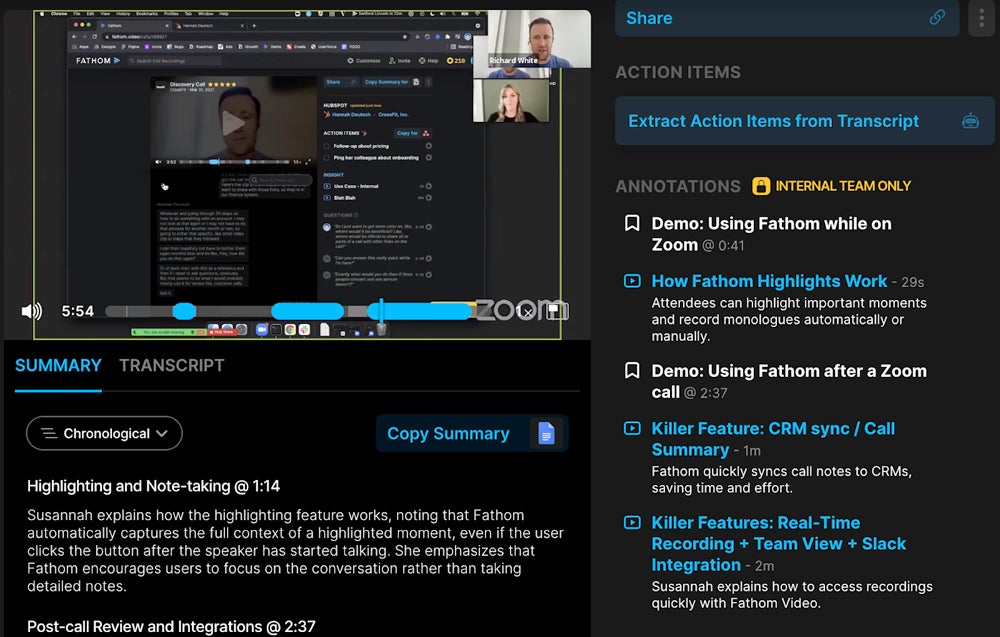
For remote teams with hybrid video setups (some people using native Zoom, others on Meet), your bot deployment logic should detect the meeting platform from the URL and route accordingly. Meet links contain meet.google.com, Zoom links contain zoom.us, Teams links contain teams.microsoft.com. Simple string matching is sufficient for detection.
Data Privacy for Remote Team Products
Meeting recordings and transcripts contain sensitive information. Remote team products need to handle this thoughtfully, especially if you're building for organizations outside your own company.
Consent disclosure: meeting bots should identify themselves by name when they join. The MeetStream API's bot_name parameter controls this. A bot named "TeamRecord Bot" announces itself clearly in the meeting UI. Organizations should inform participants that meetings are being recorded, both as a legal requirement in many jurisdictions and as a trust-building practice.
Data retention: implement configurable retention periods. Some organizations want 90-day retention for regular meetings, longer for compliance-relevant calls. The recording_config parameter on the MeetStream API controls retention at the infrastructure level. Add a user-facing configuration in your product so organizations can set their own retention policy.
Access control: transcripts and recordings should be accessible to meeting participants and designated team members, not the entire organization by default. Build a permission model from day one. It's much easier to relax permissions later than to restrict them after users are used to open access.
Frequently Asked Questions
What's the minimum viable remote meeting automation setup?
The minimum useful setup is: auto-record all team meetings, generate a structured summary with decisions and action items, and post that summary to a Slack channel. You can build this in a weekend using the MeetStream API for recording/transcription, an LLM for extraction, and the Slack API for delivery. Everything else, searchable archives, action item tracking, reminder logic, adds value but isn't required to get started. The core is getting the summary to Slack automatically.
How do you handle meetings that shouldn't be automatically recorded?
For meeting automation remote teams products, a practical pattern is opt-in per meeting type rather than always-on. Map meeting categories (1:1s, all-hands, customer calls, board meetings) to recording policies. 1:1s often require explicit consent from both parties. All-hands recordings are expected. Customer calls need disclosure. Build a policy engine in your app that checks meeting type before deploying a bot, rather than recording everything by default.
Can async meeting summaries work for meetings conducted in multiple languages?
Yes, with caveats. Transcription quality varies by language. English, Spanish, French, German, and Portuguese have strong transcription support. Less common languages may produce noisier transcripts, which affects summary quality. For multilingual teams, summarize in the language of the meeting and provide a translation into a common language (usually English) as a secondary artifact. LLMs handle translation well, so this is straightforward to implement once you have the transcript.
How do you prevent action items from being duplicated if the same task is mentioned twice in a meeting?
Deduplication at extraction time is the cleanest approach. After extracting raw action items, run a deduplication pass that compares items for semantic similarity and merges near-duplicates. A simple approach: embed all action items, compute pairwise cosine similarity, and flag pairs above a threshold (0.85 works well) for merging. The merge logic keeps the more specific version of the task description. This takes under 100ms for typical meeting action item counts and runs before any Slack post or database write.
How do you handle bot join failures when meeting links are invalid or meetings are cancelled?
Build a state machine for each bot deployment: pending → joining → inmeeting → completed. If the bot doesn't transition from joining to inmeeting within 3 minutes, mark it as failed and notify the meeting organizer via Slack DM. The MeetStream webhook bot.joining fires when the bot attempts to join, and bot.inmeeting fires when it succeeds. A timeout between these two events is your signal to surface the failure rather than silently dropping it.
If you're building a remote team productivity product, MeetStream is worth testing today. The webhook pipeline for recording and transcription works consistently across Zoom, Meet, and Teams, which is the main thing that's painful to build from scratch. Check the documentation for the full parameter reference on bot configuration.


