Speaker Diarization: Techniques, Architecture, and API Guide

Most transcription APIs give you a wall of text. No names, no turns, no structure. You get a 90-minute meeting reduced to a blob of words with no way to tell who said what. That is the problem speaker diarization solves: given an audio stream, determine WHO spoke WHEN.
Diarization is distinct from transcription. Transcription converts speech to text. Diarization segments an audio timeline into speaker-homogeneous regions and assigns each region a speaker label. When you combine the two, you get a structured transcript where each line is attributed to a specific voice. That structure is what makes downstream tasks like meeting summaries, action item extraction, and sentiment analysis actually useful.
The challenge is that real meetings are messy. Speakers interrupt each other. Background noise bleeds across channels. Remote participants join through compressed VoIP codecs. A conference room microphone captures reflections from every direction. Diarization systems have to handle all of this reliably, and in production systems, they often have to do it in real time.
In this guide we cover the main diarization techniques, the accuracy versus latency tradeoff you will face in any real deployment, and how to implement both real-time and post-call diarization using the MeetStream API. We include working Python code for parsing speaker-attributed audio frames and building a labeled transcript. Let's get into it.
What Diarization Actually Does
A diarization system operates on an audio waveform and produces a sequence of intervals, each tagged with a speaker ID. The output looks like: Speaker_0: 0.0s, 12.4s, Speaker_1: 12.6s, 31.2s, Speaker_0: 31.5s, 45.0s. These intervals are called diarization segments or speaker turns. The system does not know the speakers' names. It only knows that the voice in segment A is different from the voice in segment B.
Name assignment is a separate step. You either map speaker IDs to real names using enrollment (registering a voice print ahead of time) or you rely on the meeting platform to pass seat-based identity metadata. MeetStream takes the second approach: the binary audio frame format includes both a speaker_id (stable numeric identifier from the platform) and a speaker_name (display name the participant set). This means you get named diarization without running a separate speaker identification model.
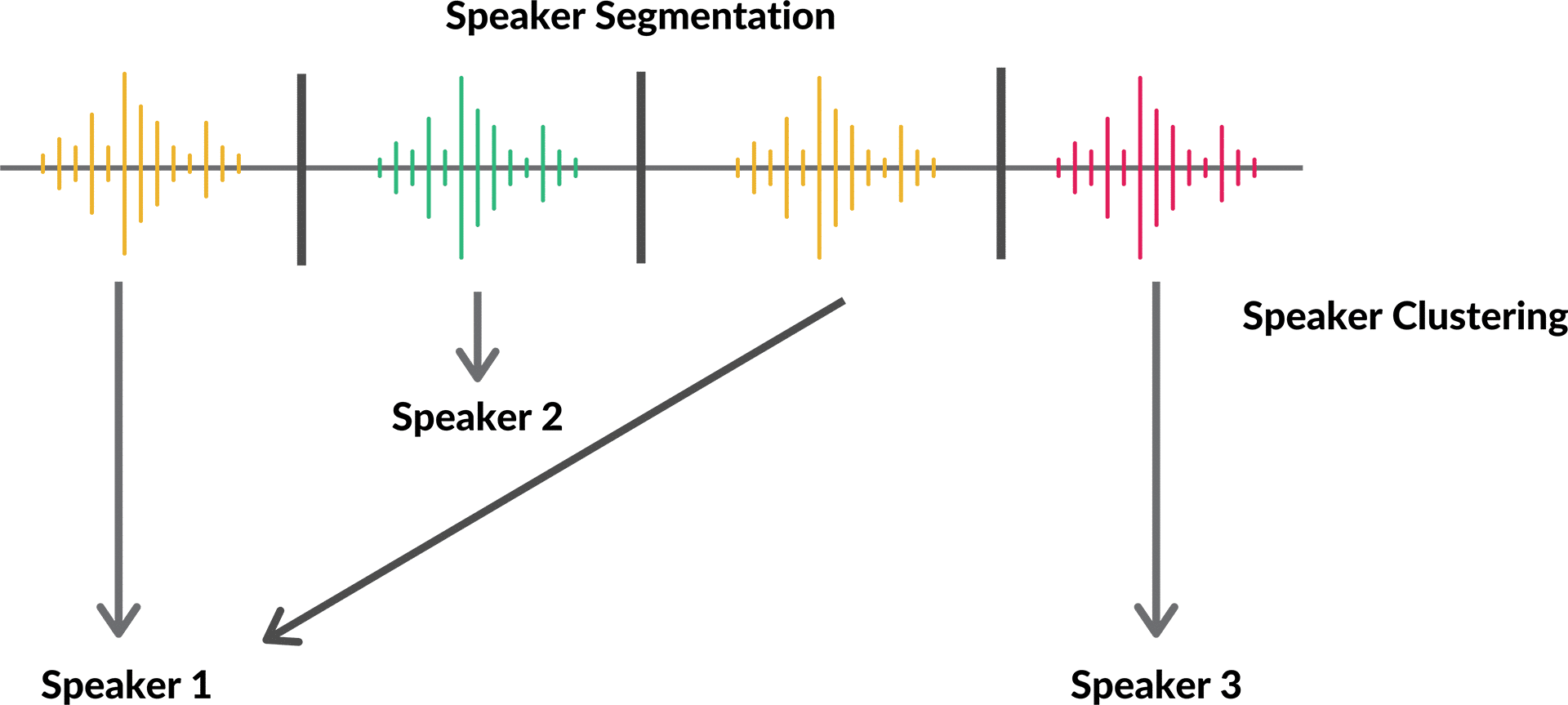
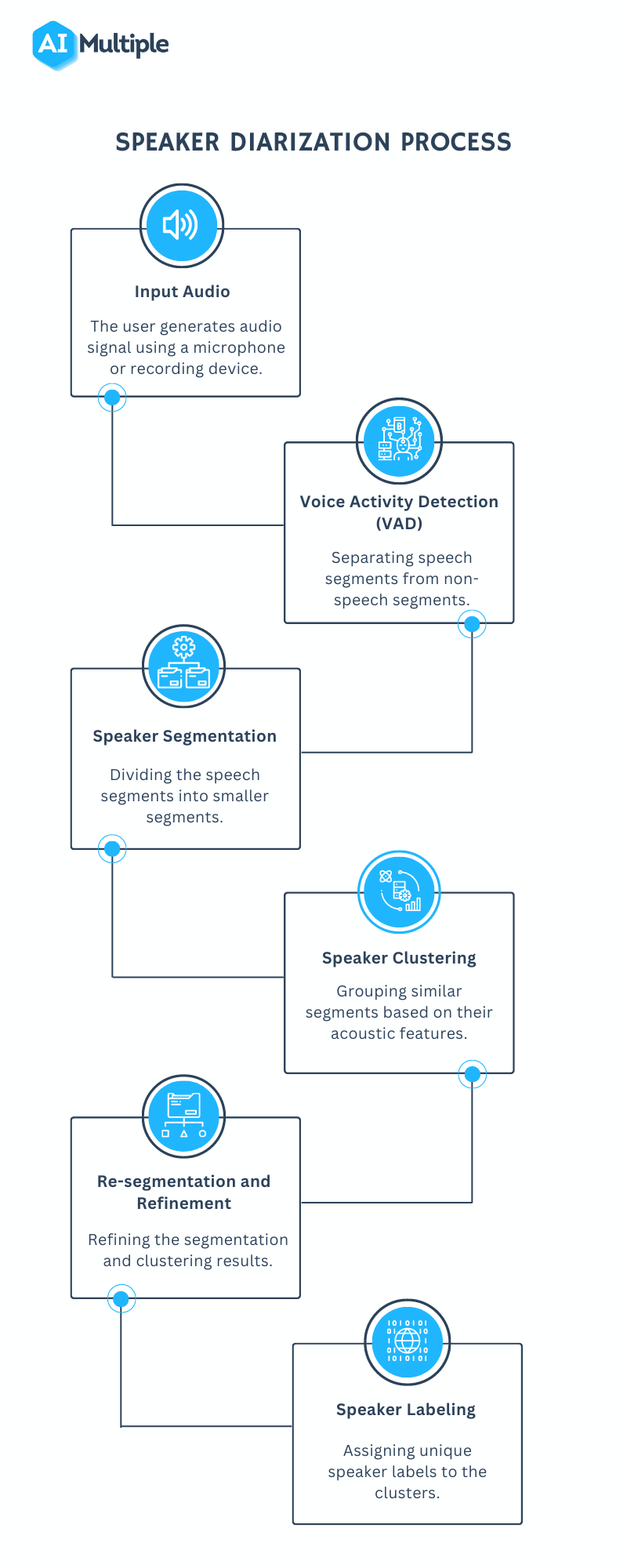
The core diarization pipeline has three stages. First, voice activity detection (VAD) identifies which portions of the audio contain speech. Non-speech regions are discarded before any further processing. Second, speaker change detection finds the boundaries between speaker turns. Third, speaker clustering groups the segments by identity, so all segments from the same voice end up with the same label.
TDNN Clustering and the x-Vector Pipeline
The dominant traditional approach uses a pipeline centered on speaker embeddings. A Time Delay Neural Network (TDNN) trained on speaker verification data maps short audio segments into a fixed-size vector space where vectors from the same speaker cluster together. These vectors are called x-vectors.

The pipeline works like this: after VAD, each speech segment is split into short overlapping windows (typically 1.5 seconds with 0.75 second hops). Each window is passed through the TDNN to produce an x-vector. Then a clustering algorithm, usually agglomerative hierarchical clustering with a cosine distance metric, groups the x-vectors. The number of clusters is either set manually or estimated using a stopping criterion like the Bayesian Information Criterion.
This approach produces high-quality results on clean recordings with well-separated speakers but struggles with overlapping speech and short speaker turns under one second. The clustering step is also inherently offline: you need all the audio before you can cluster. That makes it unsuitable for real-time applications without modification.
End-to-End Neural Diarization
End-to-end neural diarization models, most notably the EEND (End-to-End Neural Diarization) family, treat diarization as a sequence labeling problem. The model takes raw audio features (usually log-mel filterbanks) and outputs per-frame speaker activity probabilities for each of N possible speakers simultaneously. This means it can handle overlapping speech directly, unlike the clustering pipeline which assumes only one speaker at a time.
The original EEND model used a two-speaker assumption. EEND-EDA extended this with an encoder-decoder attractor mechanism that can handle a variable number of speakers. The tradeoff is computational cost and the difficulty of handling very large speaker counts in long meetings.
Pyannote.audio is the most widely used open-source library implementing state-of-the-art diarization. It provides a high-level pipeline that combines a segmentation model (which handles VAD and short-segment speaker change detection) with an embedding model and clustering. You can run it locally or fine-tune it on domain-specific data.

from pyannote.audio import Pipeline
import torch
# Load pretrained pipeline from Hugging Face
pipeline = Pipeline.from_pretrained(
"pyannote/speaker-diarization-3.1",
use_auth_token="YOUR_HF_TOKEN"
)
# Run diarization on a local file
diarization = pipeline("meeting_audio.wav", num_speakers=4)
for turn, _, speaker in diarization.itertracks(yield_label=True):
print(f"{speaker}: {turn.start:.1f}s -- {turn.end:.1f}s")
Fine-tuning pyannote on your specific meeting platform's audio characteristics (codec, sample rate, room acoustics) typically yields 10 to 20 percent relative improvement in Diarization Error Rate (DER) compared to the pretrained model.
Accuracy vs Latency: The Core Tradeoff
Post-call diarization can run the full EEND or x-vector clustering pipeline over the complete audio. It has access to the entire context, can smooth decisions backward, and can run iteratively. This produces the best accuracy, typically DER under 10 percent on clean multi-speaker recordings.
Real-time diarization must make decisions as audio arrives with latency under a few hundred milliseconds. The constraints are severe. Clustering over partial audio is unstable because you do not know how many speakers will appear. End-to-end models can run in chunks but accumulate errors at segment boundaries. In practice, real-time diarization systems use a different approach: they leverage the meeting platform's native speaker metadata.
Meeting platforms like Google Meet, Zoom, and Teams know exactly who is speaking because they route audio streams per participant. The audio from each participant arrives on a separate channel. Diarization in this context is trivial: the speaker identity is embedded in the transport layer. The challenge is accessing that per-speaker audio, which is exactly what MeetStream's live_audio_required parameter does.
Real-Time Diarization with MeetStream's Live Audio Stream
When you create a bot with live_audio_required set to a WebSocket URL, MeetStream delivers binary frames over that WebSocket connection. Each frame encodes both the speaker identity and the raw audio samples. The frame format is:

msg_type: 1 byte, always0x01for audio datasid_length: 2 bytes, little-endian unsigned short, length of speaker_id stringspeaker_id: UTF-8 string identifying the speakersname_length: 2 bytes, little-endian unsigned short, length of speaker_name stringspeaker_name: UTF-8 string, the participant's display namepcm_data: remaining bytes, PCM int16 little-endian, 48kHz mono
This frame format gives you pre-diarized audio. You do not need to run a diarization model at all because the platform has already separated the streams.
import struct
import asyncio
import websockets
from collections import defaultdict
class MeetStreamDiarizer:
def __init__(self):
self.speaker_segments = defaultdict(list)
self.current_speaker = None
self.current_segment_start = 0.0
self.sample_rate = 48000
self.bytes_per_sample = 2 # int16
self.total_samples = 0
def parse_frame(self, raw_bytes: bytes) -> dict:
offset = 0
# msg_type (1 byte)
msg_type = raw_bytes[offset]
offset += 1
if msg_type != 0x01:
return None
# sid_length (2 bytes, little-endian)
sid_length = struct.unpack_from(' dict | None:
"""Returns a speaker change event if the active speaker changed."""
speaker = frame['speaker_name']
num_samples = frame['num_samples']
timestamp = self.total_samples / self.sample_rate
self.total_samples += num_samples
change_event = None
if speaker != self.current_speaker:
if self.current_speaker is not None:
change_event = {
'previous_speaker': self.current_speaker,
'new_speaker': speaker,
'timestamp': timestamp
}
self.current_speaker = speaker
self.current_segment_start = timestamp
return change_event
async def stream_handler(websocket_url: str):
diarizer = MeetStreamDiarizer()
async with websockets.connect(websocket_url) as ws:
async for message in ws:
if isinstance(message, bytes):
frame = diarizer.parse_frame(message)
if frame:
event = diarizer.process_frame(frame)
if event:
print(
f"Speaker change at {event['timestamp']:.2f}s: "
f"{event['previous_speaker']} -> {event['new_speaker']}"
)
Post-Call Diarization with Deepgram Nova-3
For cases where you want the highest accuracy on recorded meetings, MeetStream supports post-call diarization through the recording_config.transcript provider settings. Deepgram's nova-3 model with diarize: true produces speaker-labeled transcripts after the meeting ends.
import requests
bot_payload = {
"meeting_link": "https://meet.google.com/xyz-abcd-efg",
"bot_name": "Notetaker",
"recording_config": {
"transcript": {
"provider": "deepgram",
"model": "nova-3",
"diarize": True
}
}
}
response = requests.post(
"https://api.meetstream.ai/api/v1/bots/create_bot",
json=bot_payload,
headers={"Authorization": "Token YOUR_API_KEY"}
)
bot_id = response.json()["bot_id"]
print(f"Bot created: {bot_id}")
When the transcription.processed webhook fires, retrieve the transcript from GET /api/v1/transcript/{id}/get_transcript. The response includes speaker labels on each word or utterance segment. Parse those labels to build a structured meeting record.
Building a Diarized Transcript from MeetStream Output
Whether you use live audio frames or post-call transcription, the goal is the same: a structured log with speaker attribution. Here is a pattern for merging consecutive transcript segments from the same speaker into readable paragraphs:
def build_diarized_transcript(words: list) -> str:
"""
words: list of dicts with keys: text, speaker, start_time, end_time
Returns formatted transcript string.
"""
if not words:
return ""
lines = []
current_speaker = words[0]['speaker']
current_text = []
current_start = words[0]['start_time']
for word in words:
if word['speaker'] != current_speaker:
timestamp = f"[{current_start:.1f}s]"
lines.append(f"{current_speaker} {timestamp}: {' '.join(current_text)}")
current_speaker = word['speaker']
current_text = [word['text']]
current_start = word['start_time']
else:
current_text.append(word['text'])
# flush final segment
if current_text:
timestamp = f"[{current_start:.1f}s]"
lines.append(f"{current_speaker} {timestamp}: {' '.join(current_text)}")
return '\n\n'.join(lines)
Choosing Between Real-Time and Post-Call Diarization
Use real-time diarization via live_audio_required when your application needs to act during the meeting: live coaching overlays, real-time agent handoff triggers, in-meeting sentiment monitoring, or captioning. The latency is near zero because the platform provides speaker identity natively. Accuracy on speaker attribution is perfect as long as only one participant speaks at a time on a given seat.

Use post-call diarization via recording_config.transcript when your application runs after the meeting: summary generation, CRM note population, compliance archiving, or search indexing. Post-call providers run their full models over the complete audio and produce higher confidence attributions, especially for cases where the same person joins from multiple devices or where audio quality was poor during the live session.
For applications that need both real-time and archival quality, run both in parallel. The live stream gives you immediate signal; the post-call transcript gives you the authoritative record to store.
FAQ
What is the difference between speaker diarization and speaker identification?
Speaker diarization answers WHO spoke WHEN without knowing the speakers in advance. It produces labels like Speaker_0, Speaker_1. Speaker identification maps an unknown voice to a known enrolled identity. In practice, meeting bots handle identification through platform metadata (display names) rather than voice biometrics.
How accurate is modern speaker diarization python?
State-of-the-art models like pyannote.audio 3.1 achieve Diarization Error Rates (DER) of 15 to 25 percent on challenging multi-speaker benchmarks. On clean two-to-four speaker recordings, DER can drop below 8 percent. Performance degrades with more than six simultaneous participants, overlapping speech, and low-quality audio.
Does the MeetStream API support speaker identification API for named speakers?
Yes. The live_audio_required WebSocket stream includes speaker_name in every frame, which is the participant's meeting display name. This gives you named attribution without any enrollment step. Post-call transcripts from Deepgram and AssemblyAI return speaker labels that you can map to seat-based identities using the meeting participant list.
What does multi speaker transcription accuracy depend on?
The main factors are: number of concurrent speakers (more speakers means more confusion), audio channel quality (headset versus room mic versus VoIP compression), speaking overlap frequency, and domain vocabulary (technical jargon increases word error rate). Choosing the right transcription provider for your specific meeting type matters significantly. See the provider comparison in the MeetStream docs.
Can I run pyannote.audio on MeetStream's audio output?
Yes. You can buffer the PCM frames from the live_audio_required WebSocket into a WAV file or numpy array and feed it to pyannote. However, since MeetStream already provides per-speaker streams, running a diarization model on the combined audio is redundant for most use cases. Pyannote is most useful if you are working with raw mixed-channel recordings from non-MeetStream sources.


