Multi-Speaker Transcription: Handling Multiple Voices in Meetings

A five-person meeting generates a transcript. A twenty-person all-hands generates noise. The difference is attribution: without knowing who said what, the text is a shuffled deck of statements with no ownership. Every downstream use case that matters, from CRM note population to action item extraction to compliance logging, needs named speaker attribution before it can work.
Multi-speaker transcription is the problem of producing a transcript where every utterance is tagged with the person who said it. At two speakers this is manageable with most out-of-the-box solutions. At five to twenty speakers, the engineering decisions you make about how to handle speaker attribution start to matter significantly for both accuracy and latency.
There are three distinct approaches depending on whether you need attribution in real time or post-call, and whether you care more about latency or accuracy. Each approach involves different API configurations, different data formats, and different tradeoffs in how the attribution data is structured for downstream consumption.
In this guide we cover all three: streaming speaker metadata from MeetStream's live audio frames, post-call diarization with Deepgram and AssemblyAI, and using the live transcription webhook's speakerName field. We include code for building a labeled transcript in each case. Let's get into it.
Why Multi-Speaker Attribution Is Hard
The core challenge is that audio is a single mixed signal. When five people join a conference call, the audio that reaches a recording system is an acoustic blend of all five voices. Separating that blend back into individual speakers is a signal processing problem that gets exponentially harder as participant count grows.
Three factors make meetings particularly difficult compared to controlled speech datasets. First, turn-taking is irregular. In natural conversation, people interrupt, talk over each other, and speak in fragments. Diarization models trained on clean interview data underperform significantly on spontaneous conversation. Second, audio quality varies by participant: one person on a headset microphone, another on a phone speaker in a car. Third, participants with similar voice characteristics (similar pitch, similar accent) create confusion for embedding-based clustering approaches.
The cleanest solution is to never mix the audio in the first place. Meeting platforms route audio per participant before mixing. Accessing that pre-mix, per-speaker audio is what MeetStream's live_audio_required is built to do.
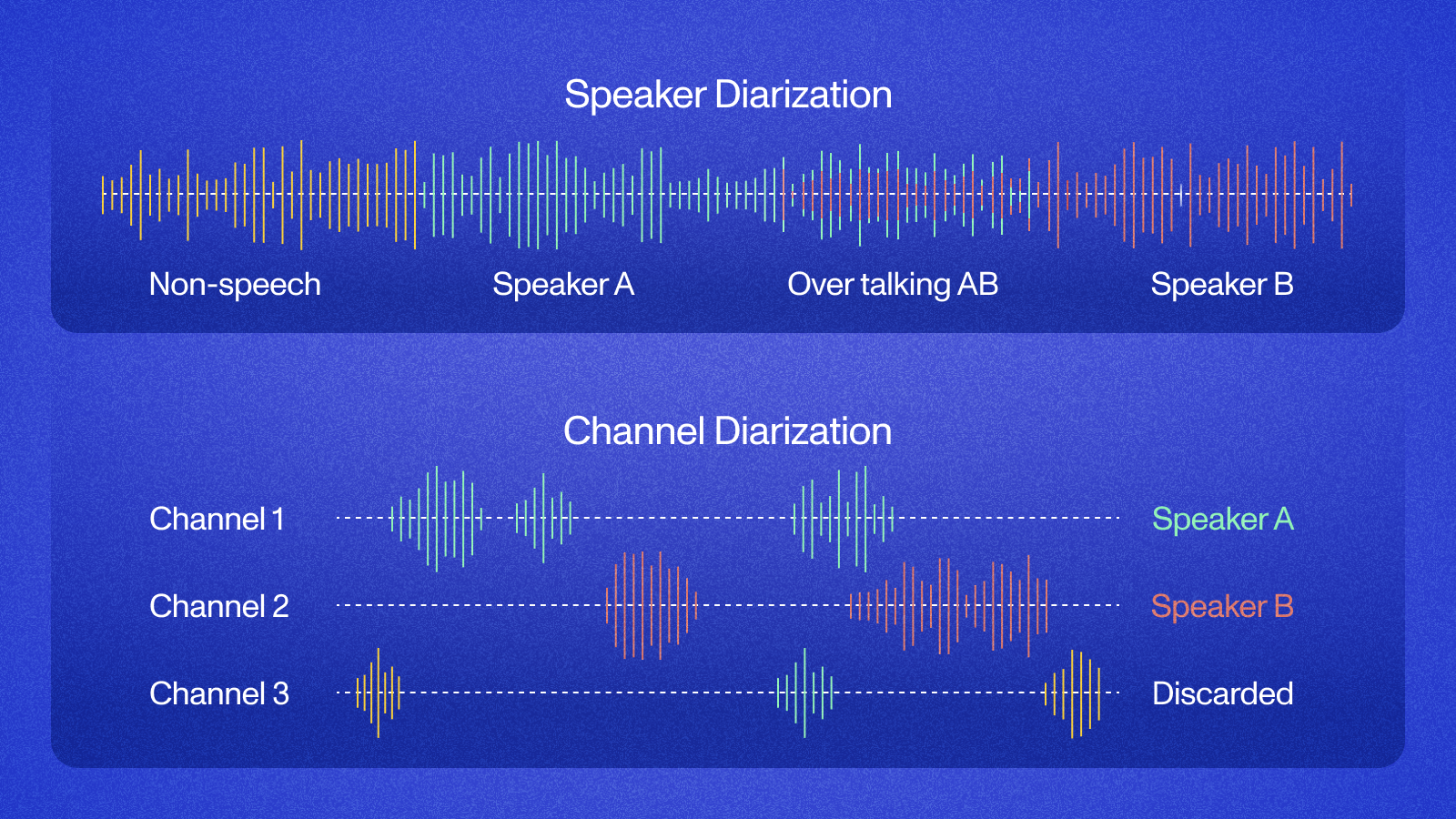
Approach 1: Streaming Speaker Metadata via live_audio_required
When you need real-time, per-speaker audio streams, use the live_audio_required parameter when creating a bot. Each binary WebSocket frame includes speaker_id and speaker_name alongside the PCM audio samples. You get attribution at the frame level, not just at the utterance level.
import requests
import asyncio
import websockets
import struct
from collections import defaultdict
# Create bot with live audio streaming
response = requests.post(
"https://api.meetstream.ai/api/v1/bots/create_bot",
json={
"meeting_link": "https://meet.google.com/abc-defg-hij",
"bot_name": "Transcript Bot",
"live_audio_required": {
"websocket_url": "wss://your-server.com/audio"
}
},
headers={"Authorization": "Token YOUR_API_KEY"}
)
bot_id = response.json()["bot_id"]
Once frames arrive, parse each frame to extract the speaker fields. This gives you pre-diarized audio at zero additional cost because the platform has already done the speaker separation at the transport layer. See the full binary frame parser in our speaker change detection guide for complete parsing code.
The resulting per-speaker audio buffers can be fed directly to a local or cloud STT model running per-speaker transcription. The resulting transcript is perfectly labeled because each audio chunk is associated with exactly one participant.
Approach 2: Post-Call Diarization with Deepgram Nova-3
When you want the highest accuracy transcript and do not need real-time results, configure the bot to use Deepgram's nova-3 model with diarization enabled. The transcript is produced after the meeting ends and delivered via the transcription.processed webhook.
bot_payload = {
"meeting_link": "https://meet.google.com/abc-defg-hij",
"bot_name": "Notetaker",
"recording_config": {
"transcript": {
"provider": "deepgram",
"model": "nova-3",
"diarize": True
}
}
}
response = requests.post(
"https://api.meetstream.ai/api/v1/bots/create_bot",
json=bot_payload,
headers={"Authorization": "Token YOUR_API_KEY"}
)
bot_id = response.json()["bot_id"]
print(f"Bot created: {bot_id}")
Deepgram's nova-3 model assigns numeric speaker labels to each word in the transcript. The challenge with post-call diarization is that you get labels like speaker_0, speaker_1, not real names. You need to map these labels to actual participant names using the meeting's participant list, which you can fetch from the MeetStream API alongside the transcript.
import requests
def fetch_and_label_transcript(bot_id: str, api_key: str) -> list:
"""
Fetch transcript and return structured list of speaker-attributed segments.
"""
resp = requests.get(
f"https://api.meetstream.ai/api/v1/transcript/{bot_id}/get_transcript",
headers={"Authorization": f"Token {api_key}"}
)
data = resp.json()
# Group consecutive words by speaker label
segments = []
current_speaker = None
current_words = []
current_start = None
for word in data.get("words", []):
speaker = word.get("speaker", "Unknown")
if speaker != current_speaker:
if current_words and current_speaker is not None:
segments.append({
"speaker": current_speaker,
"text": " ".join(current_words),
"start": current_start,
"end": word.get("start", 0)
})
current_speaker = speaker
current_words = [word.get("word", "")]
current_start = word.get("start", 0)
else:
current_words.append(word.get("word", ""))
if current_words:
segments.append({
"speaker": current_speaker,
"text": " ".join(current_words),
"start": current_start,
"end": None
})
return segments
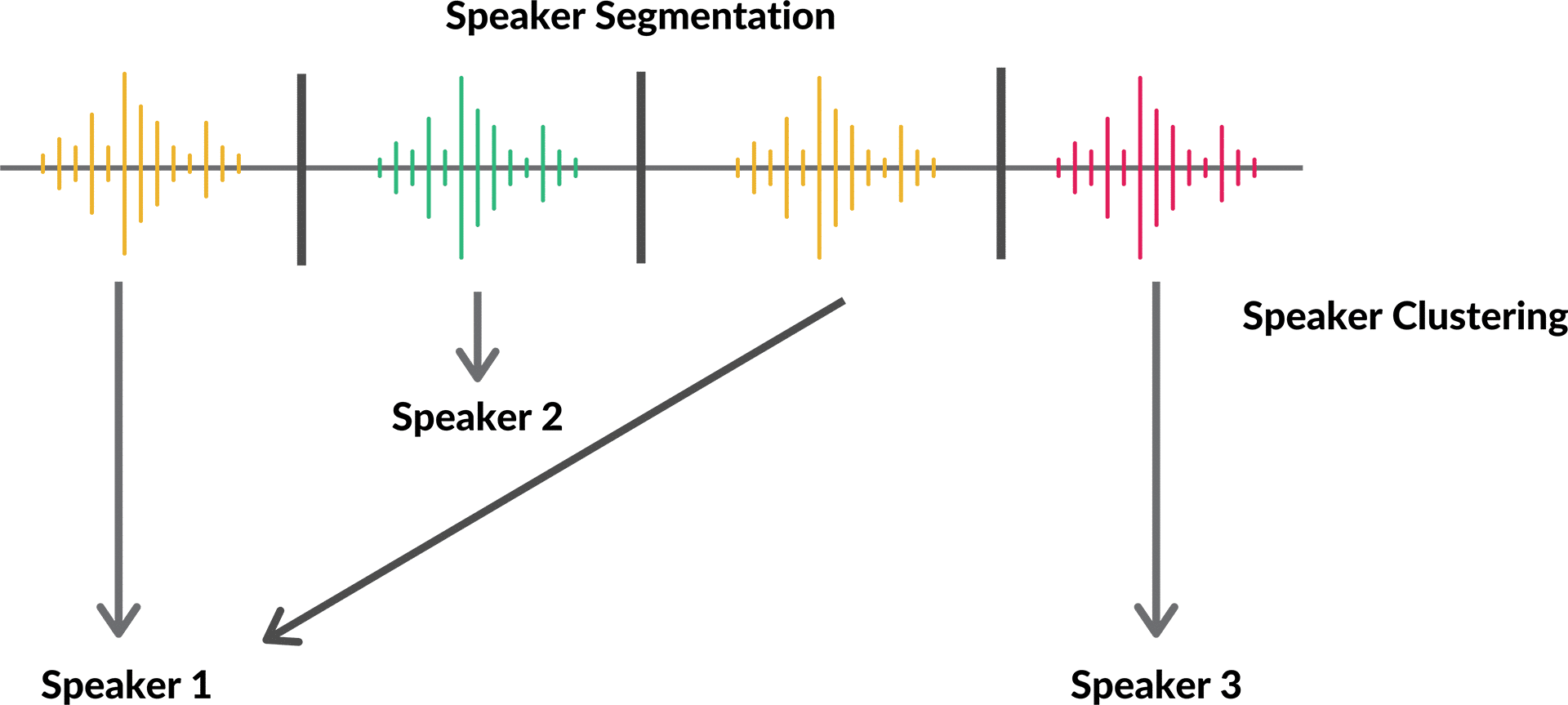
Approach 3: AssemblyAI with Speaker Labels
AssemblyAI's universal-2 model supports speaker labeling via the speaker_labels field. Configuration through MeetStream's recording_config follows the same pattern:
bot_payload = {
"meeting_link": "https://meet.google.com/abc-defg-hij",
"bot_name": "Notetaker",
"recording_config": {
"transcript": {
"provider": "assemblyai",
"speech_models": ["universal-2"],
"speaker_labels": True
}
}
}
AssemblyAI returns utterances grouped by speaker at the utterance level rather than the word level, which makes building a readable transcript slightly simpler. Each utterance object has a speaker field (A, B, C, etc.) and a text field with the full utterance.
Approach 4: Live Transcription Webhook with speakerName
The live_transcription_required parameter gives you real-time transcription results pushed to a webhook URL. Each webhook payload includes a speakerName field with the participant's display name. This is the easiest way to get named, real-time transcription without running any additional audio processing.
bot_payload = {
"meeting_link": "https://meet.google.com/abc-defg-hij",
"bot_name": "Live Transcriber",
"live_transcription_required": {
"webhook_url": "https://your-server.com/transcription-webhook"
}
}
response = requests.post(
"https://api.meetstream.ai/api/v1/bots/create_bot",
json=bot_payload,
headers={"Authorization": "Token YOUR_API_KEY"}
)
The webhook payload schema you need to handle:
# Webhook payload structure from MeetStream:
# {
# "bot_id": "bot_abc123",
# "speakerName": "Alice Chen",
# "new_text": "the word just recognized",
# "transcript": "full utterance so far",
# "word_is_final": true,
# "end_of_turn": false,
# "words": [
# {"word": "hello", "start": 1.2, "end": 1.5, "confidence": 0.98},
# ...
# ],
# "custom_attributes": {}
# }
from flask import Flask, request, jsonify
app = Flask(__name__)
transcript_log = []
@app.route("/transcription-webhook", methods=["POST"])
def handle_transcription():
payload = request.json
if payload.get("end_of_turn"):
# Commit completed utterance to transcript
transcript_log.append({
"speaker": payload["speakerName"],
"text": payload["transcript"],
"words": payload.get("words", [])
})
print(f"{payload['speakerName']}: {payload['transcript']}")
return jsonify({"status": "ok"})
Building the Final Labeled Transcript
Regardless of which approach you use, the final step is collapsing sequential segments from the same speaker into readable paragraphs. This prevents a transcript that reads like a list of one-word utterances.
def format_transcript(segments: list, merge_gap_seconds: float = 1.5) -> str:
"""
Merge consecutive same-speaker segments and format as readable transcript.
segments: list of {speaker, text, start, end}
"""
if not segments:
return ""
merged = [segments[0].copy()]
for seg in segments[1:]:
last = merged[-1]
same_speaker = seg["speaker"] == last["speaker"]
close_enough = (
seg.get("start") is not None
and last.get("end") is not None
and (seg["start"] - last["end"]) < merge_gap_seconds
)
if same_speaker and close_enough:
last["text"] += " " + seg["text"]
last["end"] = seg.get("end")
else:
merged.append(seg.copy())
lines = []
for seg in merged:
start = seg.get("start", 0)
lines.append(f"{seg['speaker']} [{start:.1f}s]: {seg['text']}")
return "\
\
".join(lines)
Choosing the Right Approach for Your Use Case
| Use Case | Recommended Approach | Latency | Attribution Source |
|---|---|---|---|
| Live coaching overlays | live_audio_required | Near-zero | Platform metadata |
| Real-time captions | live_transcription_required | 1-3 seconds | speakerName field |
| CRM note population | Deepgram nova-3 diarize:true | Post-call | Speaker cluster labels |
| Compliance archiving | AssemblyAI universal-2 | Post-call | Speaker cluster labels |
| Action item extraction | Either post-call provider | Post-call | Speaker cluster labels |
| All of the above | live_audio_required + post-call | Both | Platform + model |
When you need both real-time signal and archival-quality records, run both in parallel. Configure the bot with both live_audio_required and recording_config.transcript. The live stream gives you immediate per-speaker audio for in-meeting features; the post-call transcript gives you the authoritative labeled record.
FAQ
How many speakers can multi speaker transcription handle accurately?
With MeetStream's per-speaker stream approach via live_audio_required, there is no practical limit: each participant's audio is separate regardless of headcount. Post-call diarization models typically perform well up to eight to ten speakers and degrade noticeably above that. For large all-hands meetings with twenty or more participants, the per-speaker stream approach is strongly preferred.
What is the difference between meeting transcription multiple speakers using diarize:true vs speaker_labels:true?
These are provider-specific parameters for the same concept. Deepgram uses diarize: true in the recording_config. AssemblyAI uses speaker_labels: true. Both produce speaker-attributed transcripts; the output schema differs. Deepgram attaches speaker fields at the word level; AssemblyAI groups output into utterance objects. Check the MeetStream transcription docs for current schema details.
Can I transcribe multiple speakers api calls in parallel for faster results?
Yes. If you have per-speaker audio buffers from the live stream, you can submit transcription requests for each speaker in parallel rather than sequentially. This significantly reduces total latency when processing post-meeting audio. Use asyncio or a thread pool to submit concurrent requests to whichever provider you are using.
How do I handle speaker identification when the same person joins from two devices?
This is a known edge case. Each device gets a distinct speaker_id from the platform even if the display name is the same. Use speaker_name as the deduplication key: if two speaker_id values share the same speaker_name, merge their audio into one identity. One exception: some people join as "iPhone" or with generic names. In those cases, treat each device as a separate participant unless you have external data to resolve the identity.
Does the live transcription webhook support real-time speaker diarization?
Yes. The live_transcription_required webhook includes speakerName in every payload, so every partial and final transcript result is attributed to a named participant. You do not need to run a separate diarization model. The attribution comes from the meeting platform's participant identity, which is more reliable than acoustic diarization for well-structured meetings.
Frequently Asked Questions
What is the difference between diarization and multi-speaker transcription?
Diarization answers "who spoke when" by segmenting the audio timeline into speaker-labeled turns. Multi-speaker transcription goes further, assigning each transcribed word to a speaker. In practice, diarization runs first as a pre-processing step, and the resulting speaker segments feed into the transcription engine to produce labeled output.
How many concurrent speakers can a meeting bot accurately handle?
Most production diarization models perform well up to 8 simultaneous speakers in a structured meeting. Beyond that, accuracy degrades because cross-talk increases and speaker embeddings converge. For large panel calls, consider splitting the audio into smaller sub-meetings or filtering to active speakers using VAD before diarization.
What causes speaker ID confusion in multi-speaker transcription?
The main causes are overlapping speech, similar voice characteristics, and short utterances under 500ms that do not provide enough acoustic context. Improve accuracy by using a speaker enrollment step where known participants record a short voice sample, enabling the model to match speakers by identity rather than relying on clustering alone.
How do I handle late joiners in a multi-speaker transcript?
Assign a temporary speaker ID to each new audio stream that appears mid-call. If you are using a continuous diarization model, re-cluster speaker embeddings when new streams join. Flag segments with provisional speaker IDs and allow a 30-second enrollment window before finalizing speaker assignments in the transcript.


