Conversation Intelligence for Customer Support: What to Build

Quality assurance in a customer support organization used to mean a supervisor listening to 5% of calls, filling out a scorecard, and giving feedback in a weekly 1:1. The rest of the calls happened in a black box. Supervisors got a sample. Agents got inconsistent feedback. Problems like a specific mishandled objection type or a recurring product confusion point would persist for weeks before enough samples surfaced the pattern.
That's the problem conversation intelligence customer support tools are built to solve. When you can process every call systematically, QA becomes statistical rather than sampled. Coaching becomes targeted rather than generic. And patterns that would take a human reviewer weeks to notice become visible in hours. The tools that exist in the market today are mostly built for sales, Gong, Chorus, Salesloft. Customer support is underserved, which means if you're building in this space, you're working on a real gap.
The technical requirements for a support intelligence tool are different from a sales one. Sales tools focus on deal-stage signals and rep performance against a playbook. Support tools need to handle higher call volume, more varied topics, CSAT correlation, escalation detection, and tight integration with ticketing systems. The data model is different, the alert logic is different, the output is different.
This post covers the four core capabilities of a customer support intelligence platform and the technical pipeline for each. The recording and transcription layer uses the MeetStream meeting API as infrastructure. The NLP and ML layers are yours to design, and that's where the interesting product decisions are.
The Technical Foundation: Recording and Transcription at Scale
Before you can do any analysis, you need reliable transcripts. For a customer support use case, this means recording all support calls, not a sample, all of them, with speaker attribution (which voice is the agent, which is the customer) and timestamps at the segment level.
Bot deployment via POST https://api.meetstream.ai/api/v1/bots/create_bot with live_transcription_required: true gives you both a real-time transcript stream and a final post-call transcript via transcription.processed. For support call analysis, you'll use both: the live stream for real-time escalation detection and coaching nudges, the final transcript for QA automation, ticket creation, and CSAT prediction.
The data schema matters here. Store each transcript as a series of speaker-attributed segments: { "speaker": "agent|customer", "start_ms": integer, "end_ms": integer, "text": string, "sentiment": float }. The sentiment score can be computed post-transcription with a lightweight model. The speaker label from the transcription API usually maps to "Speaker 0" / "Speaker 1", you'll need a diarization-to-role mapping that identifies which speaker is the agent based on the first few segments (agents usually speak first and in a characteristic way).
Volume considerations: a 50-agent support team handling 20 calls per day per agent generates 1,000 transcripts daily. At 15 minutes average call duration, that's roughly 2.5 million words of transcript per day. Design your storage and indexing for this volume from the start. Partitioned tables by date, indexes on agent ID, customer ID, and ticket ID, and a full-text search index on transcript content will handle this scale comfortably in PostgreSQL.
QA Automation: Transcribe All Calls, Flag What Matters
Traditional QA requires a human to listen to a call and score it against a rubric. Automated QA runs the transcript against your rubric programmatically after every call, with no human in the loop unless a flag is raised.

A QA rubric for support calls typically covers: greeting adherence (did the agent use the approved opening?), hold time disclosure (did they ask permission before placing on hold?), proper escalation path (did they follow the protocol when the issue exceeded their scope?), resolution confirmation (did they confirm the issue was resolved before ending?), and prohibited language (aggressive tone, promises outside authority, disparagement of other agents).
-jpg.jpeg)
The technical implementation: after transcription.processed, run the transcript through a series of binary classifiers, one per rubric item. For structured rules (did the agent say "is it OK if I place you on hold?"), keyword and pattern matching works well and is fast. For qualitative rubric items (tone assessment, empathy markers), a fine-tuned classifier or a prompted LLM produces better results.
The output is a QA scorecard per call: pass/fail per rubric item, aggregate score, and flagged segments with the specific text that triggered the flag. High-volume teams should route only flagged calls to human review, calls that score 100% don't need human QA. Calls that score below a threshold or trigger a specific flag (like prohibited language) go to the QA queue. This focuses human reviewer time on calls that actually need attention rather than distributing it uniformly across all calls.
Track QA scores over time per agent, per team, and per issue category. Falling scores for a specific rubric item across a team suggest a training gap or a process change that isn't being followed. Rising scores over time after a coaching intervention measure whether the coaching worked.
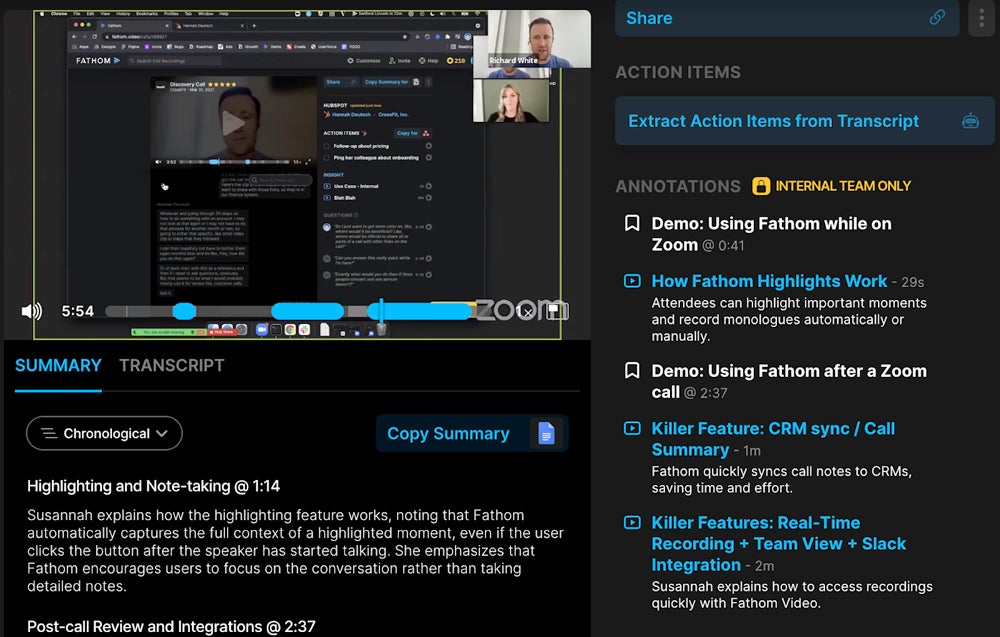
Agent Coaching: Surface Similar Past Calls
The most underutilized coaching mechanism in support is institutional knowledge: this exact problem has come up before, and here's how your best agent handled it. Most organizations don't have a way to surface that knowledge in the moment. It exists in the recordings, but nobody can query "show me how we handled refund disputes for customers in month 6 of their subscription" in real time.
Building a coaching feature on top of the transcript archive: when a support call is in progress, you're receiving a live transcript stream. As the conversation develops, you can classify the issue type and search the historical transcript database for similar resolved calls. The agent sees a panel in their support tool showing: similar past calls, how they were resolved, and whether the resolution received a positive CSAT.
The search here benefits from semantic retrieval. A customer saying "I've been charged twice and nobody seems to care" and a customer saying "there are two line items on my bill for the same service" are describing the same issue with different words. A keyword search misses the connection; a semantic search finds it. Embed transcript segments with a vector model, store in a vector database, and query with the current call's live transcript segments as the search query.
Support call transcription produces the data; the coaching feature produces the actionable surface. The latency requirement is real-time enough to be useful but not low enough to require millisecond response, 2-5 seconds to surface a coaching suggestion is acceptable for support use cases. This is achievable with a well-indexed vector store and a cached embedding model.
Post-call coaching is the other mode. After a QA flag is raised, the coaching workflow presents the agent with: the specific segment that triggered the flag, the rubric item that failed, a comparable positive example from a similar call, and a self-assessment question ("What would you do differently?"). This is dramatically more effective than telling an agent "your hold time disclosure score was low this week" without context.
Automatic Ticket Creation from Call Summaries
Support calls often generate follow-up work: a refund to process, a bug to file, a customer account to update, a callback to schedule. Today, this is the agent's responsibility to log after the call. They're under time pressure, they're moving to the next call, and ticket quality degrades. Issues get categorized wrong, descriptions are vague, customer IDs are missing.
Automated ticket creation from call summaries fixes this at the source. After transcription.processed, extract: the issue type (classified against your ticket taxonomy), the resolution status (resolved during call / requires follow-up), the specific follow-up action if any, the customer identifier, and the priority signal (express frustration or urgency mentioned by the customer).
Write this to your ticketing system, Zendesk, Freshdesk, Jira Service Management, or Linear, via their APIs. The ticket body includes the structured extraction plus a link to the full transcript for reference. The classification confidence score determines routing: high-confidence extractions go directly to the appropriate queue; low-confidence extractions go to a "review before routing" queue.
The accuracy benchmark to aim for: better than an agent who just finished a difficult call and is moving to the next one. That bar is actually achievable fairly quickly with a well-calibrated extraction prompt. Most organizations find that automated tickets have better category accuracy and more consistent descriptions than manually entered ones within a few weeks of tuning.
For meeting analytics customer success teams, the same pipeline works: post-call ticket creation, auto-populated with the right customer record, the right issue category, and the right severity level.
CSAT Prediction from Conversation Patterns
Customer satisfaction scores arrive days after the call when a survey lands in the customer's inbox. The signal is delayed, sample rates are low (most customers don't fill out surveys), and by the time the score arrives, the agent has handled hundreds more calls. The feedback loop is too slow to change behavior.
CSAT prediction closes the loop in real time. Using historical calls where CSAT scores are known, train a model to predict CSAT from conversation patterns. The features that predict CSAT well in support contexts: customer sentiment trend over the call (starting frustrated, ending neutral is better than staying frustrated throughout), number of topic shifts (more shifts correlates with unresolved complexity), resolution confirmation present, hold time count and duration, agent interruption rate, and call duration relative to issue type baseline.
A gradient boosted tree model (XGBoost, LightGBM) works well for this prediction task because the feature set is tabular and interpretable. You want to know not just the predicted CSAT score but which features drove the prediction, if a call is predicted to produce a low CSAT, the model should tell you whether it's because of hold time, or unresolved complexity, or negative sentiment trajectory. That's the actionable signal.
The real-time use case: during the call, update the predicted CSAT as the conversation progresses. If the prediction drops below a threshold, trigger a supervisor alert: "Call in progress, predicted CSAT below 3.0, agent: [name]." The supervisor can join the call or send the agent a coaching nudge. This turns CSAT prediction from a historical measurement into a real-time intervention trigger.
Accuracy will be modest at first, expect 60-65% precision in calling low-CSAT calls early in your model's life. That's still dramatically better than no prediction. As you collect more labeled examples (calls with confirmed CSAT scores), the model improves. After 10,000 labeled examples, most teams see precision above 75%.
Building the Intelligence Platform Architecture
The full platform connects: MeetStream (recording + transcription) → processing pipeline (QA automation, coaching retrieval, ticket extraction, CSAT prediction) → output layer (QA queue, agent coaching panel, ticketing system, supervisor alerts) → analytics dashboard (agent scores, team trends, CSAT correlation).
The processing pipeline should be event-driven, not synchronous. The transcription.processed webhook enqueues a job. Each analysis step (QA scoring, ticket extraction, CSAT prediction) runs as a separate job in the queue, independently retryable. Don't block ticket creation waiting for CSAT prediction to run, they're independent and should fail independently.
The analytics dashboard query layer is where the compound value emerges. Individual call analysis is useful; cross-call analytics is where patterns become visible. "Which agent has the highest CSAT prediction accuracy compared to actual CSAT?" "Which issue category has the worst first-call resolution rate?" "Which QA rubric item has declined most this month?" These queries run against your structured database, not against individual transcripts.
Frequently Asked Questions
How do you get consent for recording customer support calls?
The legal requirement is jurisdiction-specific, but the practical approach is consistent: disclose recording at the start of the call. Most support organizations include "this call may be recorded for quality and training purposes" in their opening script or IVR message. For video support calls, the MeetStream bot's visible name in the meeting ("Support Bot") provides additional disclosure. Store the disclosure confirmation as part of your call metadata. This matters for compliance in all-party consent states and GDPR-governed contexts.
What's the right QA rubric for a customer support call?
Start with the rubric your human QA team already uses, that's your calibration data. If you don't have an existing rubric, the core items that correlate with customer satisfaction in support research are: issue acknowledgment (agent demonstrated they understood the problem), resolution confirmation (explicit check that the issue was resolved), proactive information (offered relevant information the customer didn't ask for), and call closure (thanked customer, confirmed no outstanding concerns). These four items catch most of the meaningful variance in support call quality.
How do you handle multilingual support calls in a conversation intelligence system?
Transcription quality is the first consideration, verify that your transcription provider supports the languages your support team handles at production quality. Processing in the native language is generally better than transcribing then translating before analysis; translation introduces errors that compound in NLP downstream. Train separate classifiers per language where volume supports it; use multilingual models (mBERT, XLM-R) for languages with insufficient training data.
Can conversation intelligence work for chat-based support, not just calls?
Yes, and in some ways it's simpler because you already have text without the transcription step. QA automation, ticket creation, and CSAT prediction all work on chat transcripts with no modification to the downstream pipeline. The real-time coaching component is slightly different since you're not streaming audio, but the concept of surfacing similar past conversations based on the current chat context is directly applicable. Many teams start with chat (because the data is already in text format) and add call recording later.
How do you evaluate whether the CSAT prediction model is actually improving support quality?
A/B test the intervention. Randomly assign calls predicted to be low-CSAT to either receive a supervisor alert (treatment) or no alert (control). Measure actual CSAT outcomes across both groups. The difference in CSAT rate between treated and untreated groups, combined with the cost of supervisor interventions, gives you the ROI calculation. Run this for at least 500 calls per group before drawing conclusions, CSAT prediction effects are real but modest, and small samples produce noisy measurements.
If you're building a conversation intelligence product and want to test the recording and transcription infrastructure without managing platform integrations, the MeetStream API documentation covers the full bot configuration. The webhook pipeline for live transcription and post-call transcript delivery is the same regardless of whether the call is on Google Meet, Zoom, or Teams.


