Conversation Intelligence: Turning Meeting Data into Business Decisions

Zoom alone handles over 300 million daily meeting participants. Every one of those meetings generates audio, and the overwhelming majority of that audio is never analyzed beyond a vague summary written by someone who was only half-paying attention. The signal is there. The ability to extract it systematically is what separates companies that make decisions on gut from companies that make decisions on evidence.
The category that does this extraction is called conversation intelligence, and it has moved from a niche sales coaching tool to infrastructure that product, engineering, customer success, and compliance teams all depend on.
This guide covers how it works technically, what you can actually extract, where the real implementation complexity lives, and what separates a basic transcript pipeline from a production-grade conversation intelligence system.
In this guide, we'll cover the technical pipeline behind conversation intelligence, the use cases that generate the most value, tradeoffs between building and buying, and how to wire it up with a meeting bot API. Let's get into it.
What Conversation Intelligence Actually Does
Conversation intelligence is the systematic process of capturing spoken language from meetings, transcribing it, and running analysis layers on top to extract structured insight. That last part is where most implementations fall short. Transcription alone is not conversation intelligence. It is a precondition for it.
The outputs a mature system can produce include: speaker-attributed text with timestamps, topic segmentation, sentiment curves mapped against talk time, keyword and phrase frequency, question detection, monologue ratio (one speaker dominating), silence detection, filler word tracking, action item extraction, objection classification, and compliance keyword flagging. Each of these requires a different processing layer on top of raw transcript data.
Meeting intelligence at scale means this processing runs automatically for every meeting, not just the ones someone remembered to review.
The Technical Pipeline
A production conversation intelligence pipeline has several distinct stages, and understanding each one matters if you are building or evaluating a system.
-jpg.jpeg)
Stage 1: Audio capture. Before any analysis, you need to get audio out of the meeting platform. This is harder than it sounds. Zoom, Google Meet, and Teams each have different technical constraints. Some require OAuth App Marketplace approvals. Others expose audio through WebRTC streams or display capture. A meeting bot handles this by joining the call as a participant and extracting the media stream directly. The bot needs to run in an environment with a virtual display and audio sink so platforms treat it as a real user. This is not trivial infrastructure to build and maintain.
Stage 2: Speech-to-text (STT). Raw audio gets sent to a transcription provider. The main options in production use are AssemblyAI, Deepgram, and services like JigsawStack that add language auto-detection. Each has different tradeoffs on word error rate (WER), latency, speaker diarization accuracy, and support for technical vocabulary. Deepgram's nova-3 model is generally strong for real-time streaming. AssemblyAI has better entity detection in post-call processing. The choice matters because downstream NLP quality is bounded by transcript quality.
Stage 3: Speaker diarization. Raw transcript output is typically a flat text block. Diarization maps each word or segment to a speaker label (Speaker 1, Speaker 2, etc.) and, if you have a speaker directory, resolves those labels to real names. This is the step that enables per-speaker analytics. Without it, you cannot compute talk-time ratios, per-rep sentiment, or objection frequency by participant.
Stage 4: NLP analysis. This is where raw transcript becomes insight. A typical NLP layer runs several passes:
Topic modeling segments the transcript into topical blocks and labels them (pricing discussion, technical deep dive, objection handling, next steps). Models like LDA or transformer-based classifiers fine-tuned on meeting data work here.
Sentiment analysis scores each speaker turn on a positive/neutral/negative axis. The interesting signal is not a single meeting-level sentiment score but a curve over time. A call that starts positive and goes negative in the last 10 minutes looks very different from one that stays flat throughout.
Keyword and phrase extraction surfaces high-frequency terms and, if you have a domain-specific vocabulary (competitor names, product features, risk terms), flags their appearance and context.
Intent classification detects question patterns, objection patterns, and commitment language. A question is easy to detect syntactically. An objection is harder: it may sound like a question, a statement, or a hypothetical. Fine-tuned classifiers trained on labeled sales call data outperform generic models significantly here.
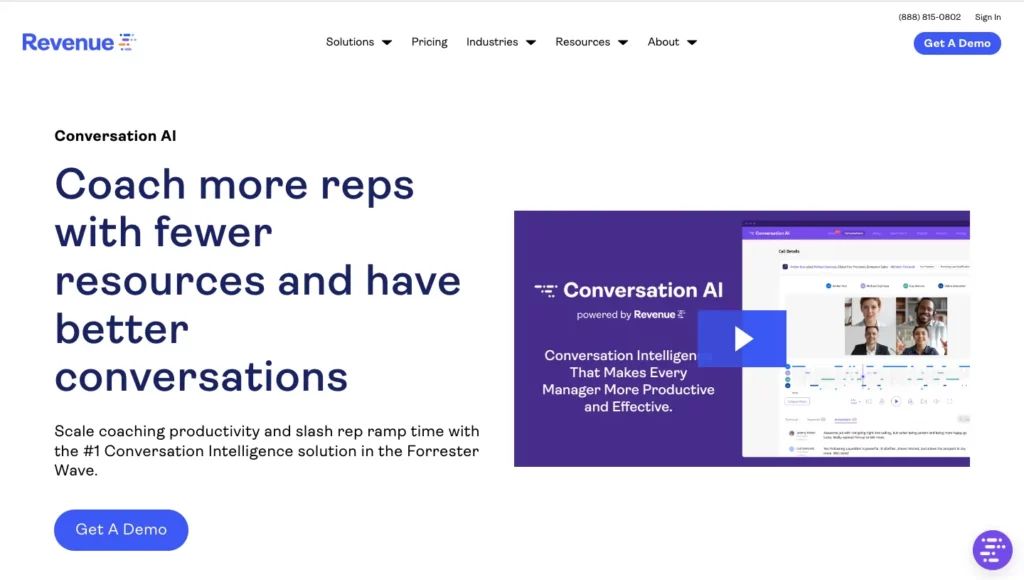
Action item extraction pulls commitment language: phrases with future tense and an owner ("I'll send you the docs by Friday", "Let's schedule a follow-up next week"). LLM-based extraction has largely replaced rule-based approaches for this task.
Stage 5: Storage and retrieval. The processed output needs to be searchable. A transcript with NLP annotations stored as structured JSON, indexed with a vector store, enables semantic search across thousands of meeting recordings. "Show me every call where a prospect mentioned compliance concerns in the last 30 days" becomes a practical query.
What You Can Actually Extract
Here is a concrete breakdown of what each business function extracts from a working conversation intelligence system.
Sales coaching. Talk-time ratio per rep vs prospect. Objection frequency and rep response patterns. How often reps ask discovery questions vs pitch. Correlation between specific talk tracks and closed deals. This is sales call intelligence in its most direct form.
Customer success. Sentiment trend across a customer's call history over time. Churn signal detection: calls where a customer uses language like "we're evaluating" or "budget freeze" or asks about data export. Health score inputs derived from engagement patterns.
Product research. Aggregate feature requests across hundreds of prospect and customer calls. Pain phrase extraction: cluster calls around recurring pain descriptors to find unmet needs. Competitor mentions with context.
Compliance and legal. Keyword flagging for regulated industries: financial services calls need to flag certain disclosures, healthcare calls need to avoid specific clinical claims. Automated review reduces manual QA workload. Full audit trail with timestamps and speaker attribution.
Voice analytics for engineering teams. If you are building a product that uses voice input, meeting data is a rich training and evaluation corpus. Real conversations are harder than synthetic test cases. Silence patterns, cross-talk, background noise, and accented speech all appear in production meeting audio in ways that benchmark datasets underrepresent.
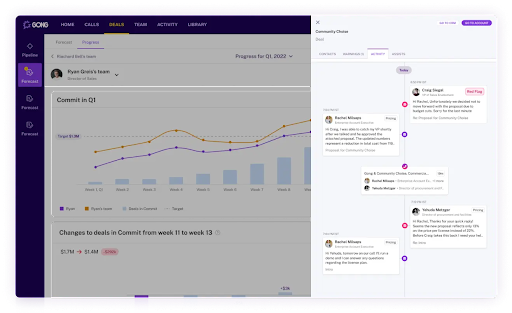
Building vs Buying the Pipeline
This is where the real architectural decision lives. The components are not novel. STT providers are accessible via REST API. NLP libraries are open source. Vector stores are commodity. The complexity is in the integration and the operational surface area.
Building in-house means: maintaining bot infrastructure for each meeting platform (Zoom API changes, Teams permission model updates, Google Meet policy shifts), handling platform-specific audio encoding and decoding, building webhook ingestion, managing transcription provider failover, building speaker diarization post-processing, and wiring all of this into a reliable delivery pipeline. Companies that have done this report 6-12 months to reach production stability. That is before any actual NLP work.
The alternative is using a meeting bot API that handles the capture and delivery layer, and building the NLP layer on top of structured webhook payloads. This is a cleaner separation of concerns. You get speaker-attributed transcript segments, raw audio per speaker if needed, and webhook events that fire reliably. Your team focuses on the analysis logic, not on keeping up with Zoom's OAuth policy changes.
The hybrid that works in practice: use a managed meeting bot API for capture and transcription. Build your own analysis layer (NLP, LLM post-processing, storage, querying) where the differentiation lives. Do not build commoditized infrastructure twice.
Real-Time vs Post-Call Processing
Most conversation intelligence use cases work fine with post-call processing. You get the transcript after the meeting ends, run your analysis pipeline, and surface insights in a dashboard or CRM. Latency of a few minutes is acceptable.
Some use cases require real-time. Live coaching overlays that show a rep's talk-time ratio during a call. Compliance keyword alerts that need to fire during the meeting, not after. Customer-facing meeting bots that respond to what participants say in real time.
Real-time processing requires streaming transcription, which has different latency and accuracy characteristics than post-call batch transcription. Streaming models optimize for low latency and return partial results that get revised as more audio arrives. The word_is_final flag in a streaming payload tells you whether a word is a partial hypothesis or committed output. Building analysis on top of streaming transcription means handling the partial/final distinction carefully, or you'll be triggering actions on transcript segments that get edited as the model hears more context.
How MeetStream Fits In
MeetStream provides the capture and transcription infrastructure layer for conversation intelligence pipelines. A single API call deploys a bot to any Zoom, Google Meet, or Teams meeting. The bot delivers speaker-attributed transcript segments via webhook, streams raw PCM audio per speaker via WebSocket for real-time processing, and supports multiple STT providers, AssemblyAI, Deepgram nova-3, JigsawStack with language auto-detection, or native meeting captions. The dashboard gives you visibility into bot status and transcript delivery. What you build on top, the NLP layer, the analysis models, the storage and search, is yours.
The Future of Conversation Intelligence
The field is moving toward ambient intelligence: systems that do not require explicit recording or bot joining, but that are always-on for any communication surface. The near-term milestone is reliable multi-language support at scale. Most current STT and NLP models degrade on non-English accented speech in ways that create quality gaps across global sales teams. The next wave of improvements in WER for accented and code-switched speech will expand the addressable use cases significantly.
LLM-based analysis has already replaced rule-based extraction for action items and summaries. The next shift is toward LLMs that can answer arbitrary queries over a corpus of meeting recordings in real time, moving from dashboard-based reporting to conversational analysis. The infrastructure requirement for that is a reliable, searchable, speaker-attributed meeting data store. That is the foundation worth building now.
Get started free at meetstream.ai.
Frequently Asked Questions
What is conversation intelligence and how does it differ from transcription?
Conversation intelligence refers to the full pipeline of capturing, transcribing, and analyzing spoken language from meetings to extract structured business insights. Transcription produces raw text. Conversation intelligence adds NLP layers on top: sentiment analysis, speaker diarization, topic modeling, objection detection, and action item extraction. Transcription is a precondition for conversation intelligence, not the destination.
What meeting intelligence data can you extract from a single call?
A production meeting intelligence system can extract speaker talk-time ratios, per-speaker sentiment curves, topic segments with timestamps, question and objection frequency, keyword and competitor mentions with context, action items with attributed owners, silence and filler word patterns, and monologue detection. The richness depends on transcript quality and the NLP models you run on top.
How does real-time voice analytics differ from post-call analysis?
Real-time voice analytics requires streaming STT, which returns partial word hypotheses before the speaker finishes a sentence. Post-call analysis processes the complete audio in batch and typically produces higher accuracy transcripts. Real-time enables live coaching overlays, in-meeting compliance alerts, and interactive meeting bots. Post-call analysis is better suited for high-accuracy summarization, CRM updates, and trend reporting. Many production systems use both.
Is building a conversation intelligence pipeline in-house realistic?
Building the full stack in-house, bot infrastructure, platform integrations, transcription pipeline, NLP analysis, typically takes 6-12 months to reach production stability before you build any differentiated analysis logic. The common pattern is to use a managed meeting bot API for the capture layer and build the NLP and analysis layers in-house where the differentiation lives.
What STT providers work best for sales call intelligence?
Deepgram nova-3 is strong for real-time streaming with low latency. AssemblyAI performs well for post-call batch processing with better entity detection and speaker diarization. JigsawStack adds automatic language detection, useful for multilingual sales teams. The right choice depends on whether you need real-time processing, how much you care about accuracy vs latency, and whether your call corpus is multilingual.


