AI Meeting Assistant: Features, Architecture, and How to Build One

Most teams evaluate AI meeting assistants the way they evaluate SaaS tools: they open a feature comparison page, check the boxes, and pick the one with the most ticks. That works fine if you are buying a tool for internal use. It breaks down the moment you want to embed meeting intelligence into a product you are building, or customize how meeting data flows through your stack.
The shift from buyer to builder changes what features matter and why. A buyer cares about the quality of the output. A builder cares about the quality of the API surface, the reliability of the webhook delivery, and whether they can plug in their own transcription provider or push to their own storage.
This article covers both perspectives: what defines a well-built AI meeting assistant, how each capability works technically, and what the implementation looks like if you are building one with a meeting bot API rather than buying a prepackaged tool.
In this guide, we'll cover the features that matter most, the architecture behind each one, a practical comparison of passive tools vs. what you can build, and how to get started. Let's get into it.
The Core Feature Set
A complete AI meeting assistant has five capability layers. Each layer builds on the previous one, and the quality of each layer bounds the quality of everything above it.
Transcription Accuracy and Provider Choice
Transcription is the foundation. Word error rate (WER) varies significantly across providers, meeting conditions, and speaker profiles. In clean audio with native English speakers, modern STT models from AssemblyAI and Deepgram achieve WER under 5%. That number climbs with accented speech, cross-talk, technical vocabulary, or poor audio input from a conference room microphone array.
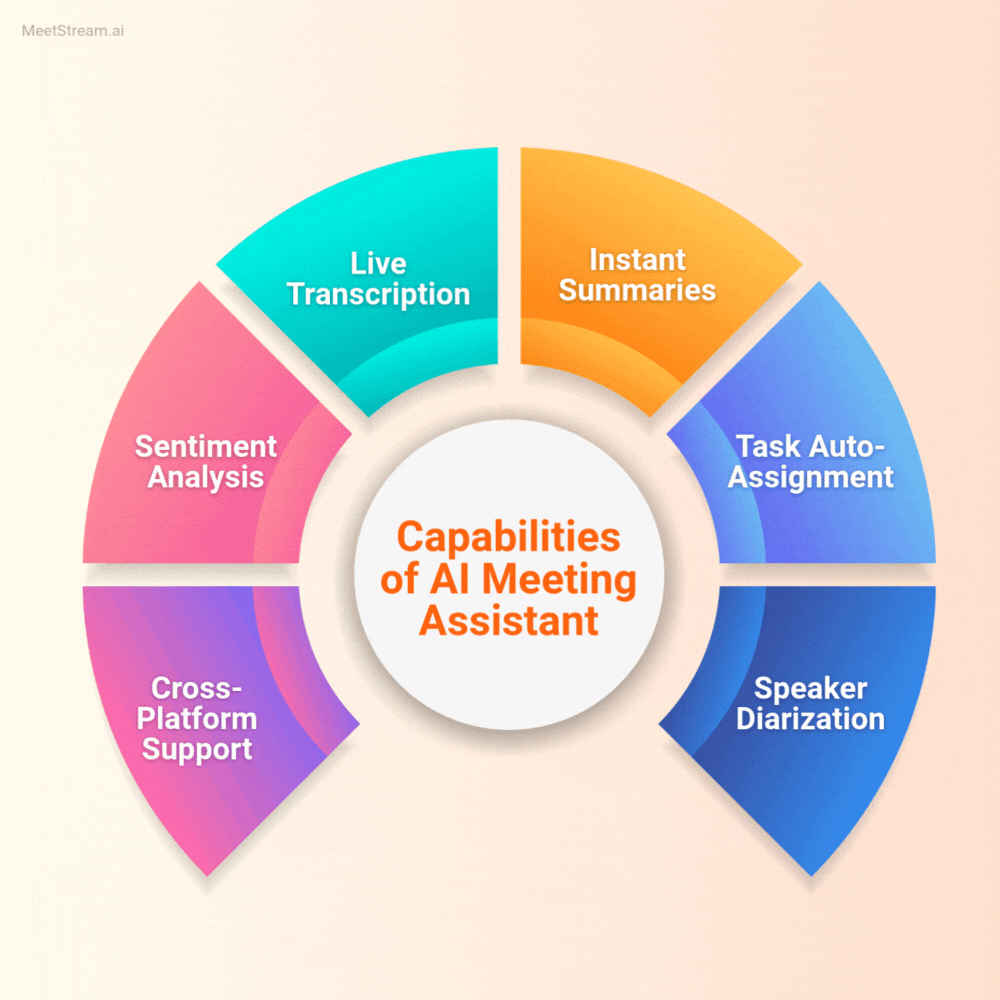
For a prepackaged AI meeting assistant, you get whatever transcription provider the vendor chose. For a builder, this is a real architectural decision. Different providers have genuine tradeoffs:
Deepgram's nova-3 model is optimized for low-latency streaming and performs well on telephony-grade audio. AssemblyAI has stronger entity detection and better speaker diarization on post-call batch processing. JigsawStack adds automatic language detection, which matters if your meetings are multilingual. Native meeting captions (pulled from the platform's own captioning system) are highest latency but require no external API call.
If you are building a product where transcription quality directly affects user trust, the ability to swap providers or route different call types to different providers is a meaningful architectural advantage.
Speaker Diarization
Raw transcripts are not useful for analysis. A flat block of text with no speaker attribution cannot tell you anything about who spoke when, how much each participant talked, or whether the sales rep asked any questions. Speaker diarization maps each word or segment to a speaker and resolves those labels to participant names where possible.
Diarization accuracy degrades with overlapping speech and similar-sounding speakers. The current best approach is a combination of the STT provider's built-in diarization and a post-processing layer that aligns transcript segments with participant metadata from the meeting platform (names from the attendee list, if available).
For builders, the key requirement is that the meeting bot delivers speaker-attributed transcript segments, not flat text. When building on the MeetStream API, each transcript segment in the webhook payload includes speaker name and timestamp, which you can pass directly to your analysis layer without any additional diarization work.
Action Item and Summary Extraction
This is where most consumer AI meeting assistants focus their marketing. Action item extraction and meeting summarization are the outputs that end users see and judge. The technical implementation underneath ranges from simple rule-based pattern matching to LLM-based extraction with structured output.
Rule-based extraction catches explicit commitment language: "I'll send", "let's schedule", "can you follow up". LLM-based extraction catches implicit commitments and inferred next steps that never get stated explicitly but are implied by the conversation. The gap between these two approaches is significant in real sales and customer success calls, where commitments are often soft and contextual.
When building your own assistant, the cleanest pattern is: receive the complete speaker-attributed transcript via webhook, pass it to an LLM with a structured output schema, get back a JSON object with summary, action_items (each with owner, task, due_date), decisions, and topics. This is a solved problem with modern LLMs. The reliability bottleneck is transcript quality, not the LLM prompt.
Integrations: CRM, Slack, and Notion
Integrations are where most consumer meeting assistants spend significant engineering resources building one-off connectors. For builders, integrations are just webhook handlers. Your meeting bot delivers the transcript and metadata to a webhook endpoint you control. From there, you write to whatever downstream system makes sense: push to HubSpot, post a summary to a Slack channel, create a Notion page, update a Google Sheet, or fire into your own database.
This architecture is genuinely more flexible than buying a tool with a fixed integration list. It also means you own the integration logic, including handling failures, retries, and schema mapping. The tradeoff is engineering time vs. flexibility.
One pattern that works well: use the custom_attributes field on the bot creation request to pass context that comes back with every webhook event. If you pass {"crm_deal_id": "123", "team": "enterprise"} when creating the bot, that data returns with the transcript webhook, and your handler can route to the right CRM record without any additional lookup.
Real-Time Coaching and Live Features
Live meeting features, talk-time overlay, real-time transcription, in-meeting alerts, require streaming audio, not post-call batch processing. The technical architecture is meaningfully different.
Real-time coaching works by connecting to a WebSocket that streams PCM audio per speaker as the meeting progresses, running streaming transcription (Deepgram streaming or AssemblyAI streaming), and applying lightweight classifiers or LLM prompts to detect coaching moments: excessive monologue, competitor mentions, pricing objections, questions being asked.
The streaming transcript payload includes word_is_final and end_of_turn flags. You should build your analysis triggers on final words and end-of-turn boundaries, not on partial hypotheses. A classifier that fires on a partial word that gets revised will produce false positives and degrade coach trust quickly.
Searchability and Historical Analysis
The value of a meeting assistant compounds over time if you build proper storage and retrieval. A single well-summarized call is useful. A searchable corpus of 500 calls from the past year is a strategic asset: you can answer questions like "What are the top three objections from enterprise prospects?", "How has our demo-to-pilot conversion rate correlated with specific talk tracks?", or "Which product features have prospects requested most often this quarter?"

Building this requires: structured storage of speaker-attributed transcripts with metadata (date, participants, deal ID, company), vector embeddings for semantic search, and a query interface. This is not complex to build with current tools, but it requires deliberate architecture decisions upfront.
Feature Comparison: Passive Tools vs Building with MeetStream
| Capability | Consumer AI Meeting Tool | Building with Meeting API |
|---|---|---|
| Transcription provider | Fixed (vendor chooses) | Configurable: AssemblyAI, Deepgram, JigsawStack, captions |
| Speaker diarization | Built in, not customizable | Speaker-attributed segments in webhook payload |
| Action item extraction | Pre-built templates | Custom LLM prompt with your output schema |
| CRM / Slack sync | Fixed connector list | Any destination via webhook handler |
| Real-time audio | Available in some tools | PCM16 WebSocket stream per speaker, 48kHz |
| Custom data on bot | Not supported | custom_attributes pass-through on every event |
| AI agent in-meeting | Not available | MIA: deploy agent with voice/chat/action capabilities |
| Multi-platform | Zoom + Meet (varies) | Zoom, Google Meet, Teams via one API |
| Data ownership | Vendor stores transcripts | Your infrastructure, your retention policy |
How MeetStream Fits the Builder Architecture
MeetStream handles the infrastructure layer that most teams underestimate: getting a reliable, speaker-attributed media stream out of Zoom, Google Meet, and Teams without maintaining three separate platform integrations. A single API call creates a bot that joins the meeting, records or streams audio and video, delivers transcript segments per speaker via webhook, and supports configurable transcription providers. The API reference covers the full bot creation parameter set including real-time streaming endpoints, agent configuration, and calendar integration.
Getting Started
The minimal working implementation is: create a bot on a meeting link, set a callback_url, receive the transcription.processed webhook event, pass the transcript to your LLM, and push the output wherever it needs to go. The entire pipeline takes less than a day to wire up. The meeting assistant features you build on top are where your team's time is better spent.

Get started free at meetstream.ai.
Frequently Asked Questions
What features should an AI meeting assistant include?
A complete AI meeting assistant needs accurate transcription with speaker diarization, action item and summary extraction, integration hooks for CRM and messaging tools, searchable storage of past meeting content, and optionally real-time coaching features. For developers building a custom assistant, the ability to configure transcription providers and receive structured webhook payloads is critical.
How does an AI meeting assistant extract action items?
Modern AI meeting assistants use LLM-based extraction rather than rule-based keyword matching. The complete speaker-attributed transcript is passed to a language model with a structured output schema. The LLM identifies explicit commitments, implied next steps, owners, and deadlines. LLM-based extraction outperforms rule-based approaches on realistic sales and customer success calls where commitments are often indirect.
What is the difference between AI meeting assistant tools and building with a meeting bot API?
Consumer AI meeting assistant tools are fixed-feature products where the vendor controls transcription quality, integration options, and data retention. Building with a meeting bot API gives you configurable transcription providers, custom integration logic via webhooks, your own data storage, and the ability to add AI agent capabilities inside meetings. The tradeoff is engineering time in exchange for flexibility and ownership.
How do best AI meeting assistant tools handle real-time features?
Real-time features require streaming audio over WebSocket rather than post-call batch processing. The meeting bot streams PCM audio per speaker as the meeting progresses. Streaming STT models like Deepgram nova-3 return low-latency partial and final transcripts. Coaching logic runs on final words and end-of-turn events to avoid triggering on partial hypotheses that get revised as the model hears more context.
Can I use meeting AI tools with my own CRM and data stack?
With a meeting bot API, yes. The API delivers transcript data and meeting metadata to a webhook endpoint you control. Your handler writes to any downstream system: HubSpot, Salesforce, Slack, Notion, your own database. The custom_attributes parameter lets you attach deal IDs or team context at bot creation time so webhook handlers can route to the correct CRM records without additional lookups.


